
Remember me





This section explains the overall research methodology we followed during the paper selection process. We adopted a Preferred Reporting Items for Systematic reviews and Meta-Analyses (PRISMA) methodology to ensure the accuracy and reliability of our findings. The PRISMA statement is a widely recognized guideline for conducting and reporting systematic reviews and meta-analyses. It provides a checklist of preferred reporting items to help authors improve the transparency and completeness of systematic review publications [9]. The methodology comprised several key stages, which are explained in the following sections.
We began with a comprehensive search strategy across multiple databases to identify relevant studies, followed by screening based on predefined inclusion and exclusion criteria. Next, the full texts were assessed for eligibility, ensuring only high-quality studies were included. Finally, the data was extracted, synthesized, and analyzed to draw the study’s conclusions. This systematic approach helps minimize bias and ensures transparency, as recommended by the PRISMA 2020 guidelines [10].
2.1 Search strategyThis research was conducted in August 2024 with the aim of carrying out a systematic review on the tokenization of EHR and healthcare data. The review sought to identify and analyze the most current and relevant publications on this topic.
The review targeted English-language journal articles published between 2017 and 2024, ensuring the inclusion of the latest research in this rapidly evolving field. Three reputable databases were utilized for the literature search: Web of Science Core Collection [11], IEEEXplore [12], and Scopus [13].
The search terms were carefully crafted to capture articles addressing tokenization in the context of EHR, healthcare records, and related technologies. Keywords such as “Tokenization,” “EHR,” “EMR,” “Healthcare data,” “Clinical Data,” “Patient Records,” “NLP,” “Natural Language Processing,” “Text Mining,” “Blockchain,” “Machine Learning,” and “AI” were incorporated into the final search query. Additionally, the search was limited to journal articles and review papers to ensure the inclusion of high-quality, peer-reviewed publications.
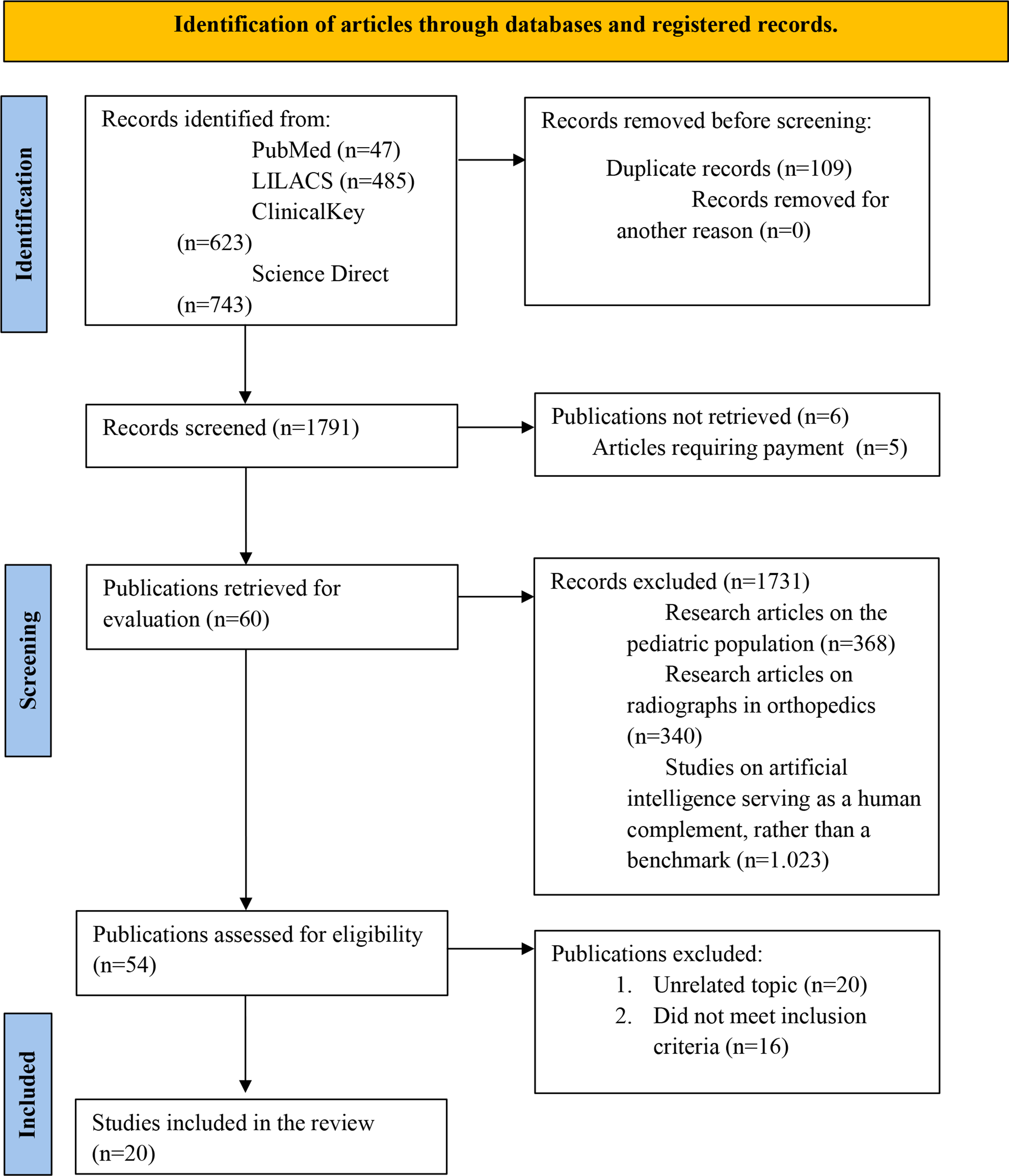
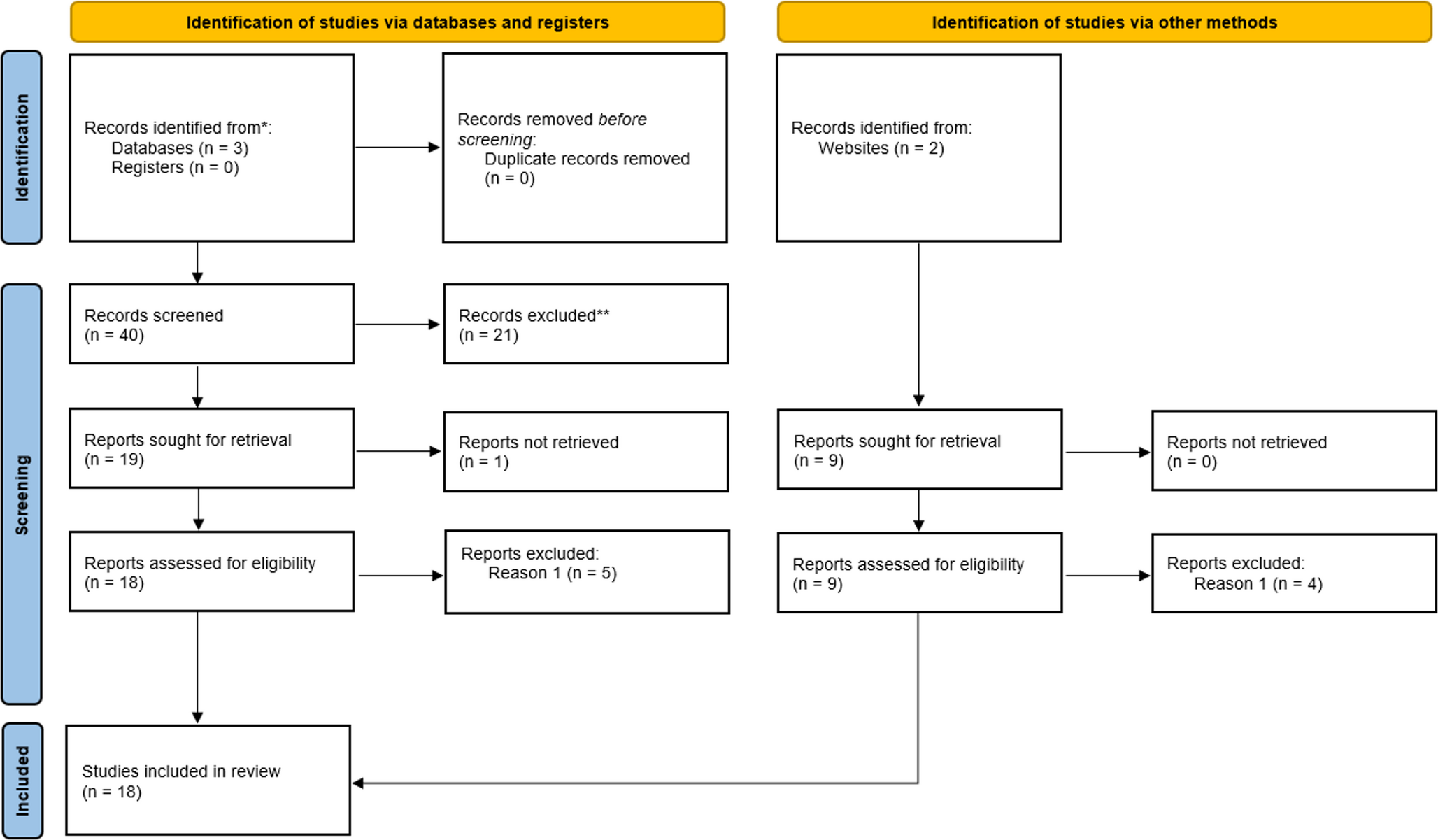
Fig. 1
Figure 1 of the PRISMA flow diagram provides a comprehensive overview of the study selection process used in this research. We employed the two main approaches to find relevant studies - identification through databases and registers and identification through other methods.
The database and register search pathway initially yielded 40 results, all from the Scopus website, with no duplicates present. These papers underwent a preliminary selection process where their abstracts were analyzed, resulting in the exclusion of 21 articles that did not fully align with the search objectives. In the subsequent round, one article was excluded due to retrieval issues, leaving 19 papers for further consideration. The remaining articles were then screened in their entirety, leading to the exclusion of 5 papers that did not sufficiently focus on tokenization, the primary theme of this review.
The second pathway, identification of studies via other methods, produced 9 results, all of which were successfully retrieved. These articles were subjected to a comprehensive analysis to determine their relevance to tokenization and potential contribution to the review. This process led to the exclusion of 4 articles. The remaining 5 articles were then combined with the 13 papers from the first pathway, resulting in a total of 18 articles for in-depth review.
By employing these two complementary approaches, we significantly enhanced our ability to identify all relevant literature on the tokenization of electronic health records and healthcare data. This dual-pronged methodology strengthens the validity and comprehensiveness of the systematic review, ensuring that the final set of included studies provides a robust foundation for subsequent analysis and synthesis. The rigorous selection process across both pathways ensures that only the most pertinent and high-quality studies are included, thereby enhancing the overall quality and relevance of our review.
2.2 ResultsThis chapter presents a comprehensive analysis of the findings from our literature review on tokenization in healthcare data analysis. Our examination of the current research landscape reveals a multifaceted picture of tokenization’s role, applications, and challenges in the healthcare domain. The results are organized into three main sections to provide a structured overview of the field: Data Analysis, Technological Advancements and Implementations and Challenges and Limitations of the studies.
Through this structured presentation, we aim to provide a clear and comprehensive picture of the state of tokenization in healthcare data analysis, setting the stage for the discussion that will follow.
2.3 Data analysisTokenization plays an important role across the reviewed articles, particularly in preprocessing EHR and clinical text for various NLP tasks. In many studies, tokenization is applied to transform unstructured text into structured data that can be analyzed using machine learning models. For example [14] and [15], use tokenization as an initial step in segmenting clinical text into tokens, facilitating further tasks like named entity recognition (NER) and predictive modeling. Both papers demonstrate how tokenization helps break down medical narratives and clinical notes into manageable units, allowing deep learning models to capture relevant patterns and improve the accuracy of the extraction and classification processes.
Tokenization also appears as a core preprocessing step in studies that focus on improving data quality and text normalization [16] and [17]. emphasize tokenization’s role in handling noisy healthcare data, such as EHRs and clinical notes. Both studies focus on text normalization techniques, including tokenization, stop word removal, and punctuation filtering, to enhance data quality and improve machine learning model performance. The use of tokenization to standardize text, particularly in multilingual or complex medical terminologies, highlights its importance in reducing variability and improving NLP outputs across diverse healthcare settings.
Articles [18, 19] demonstrate the use of tokenization in conjunction with advanced NLP models, especially transformers and BERT-based models. Both utilize tokenization within transformer models, specifically through WordPiece and subword tokenization techniques. These techniques break down complex medical terminology into subwords, enabling the models to handle rare or out-of-vocabulary terms more effectively. Tokenization in these models ensures that medical terms are processed accurately, leading to improved outcomes in entity recognition and patient outcome predictions. Similarly, in [20], tokenization is crucial in transforming texts into manageable tokens that are used in large language models (LLMs) and multimodal LLMs for clinical decision-making.
In [21] it is presented a novel hierarchical framework for medical NLP, where tokenization is used as an initial step in the processing pipeline. The framework breaks down medical text into individual tokens that represent surface-level words, forming the basis for further semantic analysis. The paper proposes a hierarchical processing model inspired by human cognition, where tokens are transformed into logical representations of meaning. This hierarchical tokenization approach allows the system to progressively build higher-level interpretations from simple word tokens, ultimately enabling more complex understanding tasks like semantic memory and predictive coding. By organizing tokenization within a cognitive-inspired architecture, the framework facilitates more transparent and explainable NLP models, particularly in the medical domain.
In studies focused on patient data privacy and secure data sharing, tokenization is utilized to anonymize and protect sensitive information [22] and [23]. both highlight the use of tokenization to convert patient data into secure tokens, ensuring privacy during data exchanges across healthcare providers. In these cases, tokenization is used not just for data structuring, but also for generating encrypted tokens that safeguard patient privacy while enabling linkage across diverse datasets. This approach facilitates secure, large-scale analysis of healthcare data while ensuring compliance with data protection regulations.
Some articles [24, 25], use tokenization to deal with complex or irregular clinical data. The two of them discuss innovative methods of tokenizing continuous and discrete EHR data to improve the performance of machine learning models in predicting patient outcomes. These studies use tokenization to handle time-series data, converting it into sequences of tokens that can be fed into transformers or autoregressive models. By tokenizing both static and dynamic clinical measurements, these models can process data more effectively, improving their predictive power and interpretability in critical care settings.
Moreover, several studies use tokenization to enhance sentiment analysis and emotion recognition in healthcare contexts [26] and [27]. both employ tokenization to preprocess unstructured healthcare data, converting text into word tokens or vectors that can be analyzed for patterns related to emotions or behaviors. These tokenization strategies are essential for creating structured datasets from free-text medical notes, enabling accurate predictions in areas like mental health and smoking behavior classification.
Tokenization is also employed in domain-specific tasks such as medical entity extraction and disease diagnosis. In [28] and [29], tokenization is used to segment clinical texts and extract key medical entities such as disease diagnoses, treatment details, and biomarkers. These studies rely on tokenization to ensure that relevant medical terms are identified and processed efficiently, improving the accuracy of clinical entity recognition and information extraction tasks. Likewise, the study [30] emphasizes tokenization as a foundational step in preparing clinical notes for tasks like named entity recognition and relation extraction, further underlining its critical role in healthcare NLP pipelines.
In article [31], tokenization plays a crucial role in analyzing clinical discharge summaries for patient phenotyping, which involves predicting ten patient disorders. The study uses tokenization to segment text into word-level and sentence-level tokens, which are then processed through a convolutional neural network (CNN) model. The authors highlight that only a small fraction of the tokens contributes significantly to the classification tasks, with token selection mechanisms employed to improve the model’s interpretability and performance. This selective use of tokens enhances the explainability of the CNN’s predictions, particularly for rare disorders like chronic pain, demonstrating the importance of token quality in patient classification from EHRs. Tokenization in this context enables a focused analysis of relevant linguistic features, which leads to moderate improvements in classification accuracy over traditional models. Table 1, resume this major findings.
Table 1 This table summarizes the key findings related to the role of tokenization in healthcare data analysis and natural Language processing (NLP)2.4 Technological advancements and implementationsA prominent development in this field is the integration of tokenization with advanced deep learning models, particularly transformers and BERT-based architectures. For example [18] and [19], demonstrate how subword tokenization techniques, like WordPiece, are essential for breaking down complex medical terminology. These advancements enable models to handle rare or out-of-vocabulary terms, improving their performance in clinical entity recognition and predictive modeling. This shift towards transformers and BERT highlights the growing reliance on sophisticated tokenization methods to manage specialized healthcare texts.
Tokenization has also advanced in its role in generating secure, privacy-preserving datasets, in a way to secure data but also to anonymize it, enabling secure data exchanges across healthcare systems [22, 23]. These advancements ensure that sensitive patient information is protected while still allowing comprehensive data analysis across multiple platforms, showcasing the growing intersection between tokenization and blockchain technologies for secure healthcare applications.
Another key advancement is the application of tokenization in dynamic healthcare data, particularly time-series data. In [24] and [25], tokenization is used to handle continuous and discrete EHR data in real-time, facilitating accurate patient outcome predictions. These innovations in handling time-series data show the expanding utility of tokenization beyond static textual data, enhancing its role in real-time clinical decision support systems.
This is the major findings but on Table 2 we provide also criticisms of this approach.
Table 2 This table provides a concise overview of the key criticisms of the findings from the literature reviewThis table provides a concise overview of the key criticisms of the findings from the literature review.
2.5 Challenges and limitations of the studiesDespite these advancements, several challenges and limitations related to tokenization persist across the reviewed literature. One of the major challenges is scalability. Studies such as [31] reveal that token selection strategies are crucial for improving performance in patient phenotyping models. However, the limited number of informative tokens and the need for larger sample sizes restrict the scalability of such models, especially in handling complex, unstructured clinical texts. Similarly, the need for more advanced architectures to fully exploit tokenization remains an issue, as demonstrated by the moderate improvements in deep learning models in this context.
Integration issues with legacy systems also present significant challenges. Articles like [23] report difficulties in integrating tokenization frameworks within existing healthcare infrastructures, particularly when using blockchain for secure data exchanges. The complexity of implementing tokenization in a way that supports legacy systems while maintaining efficiency and security is an ongoing limitation that requires further research and development.
Another key limitation is the risk of re-identification, particularly when dealing with sensitive healthcare data. Although tokenization enhances privacy by anonymizing patient information, as seen in [22], there are still concerns about the robustness of these techniques in protecting against data re-identification attacks. Moreover, tokenization in time-series data models, such as those discussed in [25], faces challenges in maintaining patient privacy while ensuring that predictive models remain accurate and effective. Addressing these privacy concerns requires more advanced tokenization strategies, such as integrating differential privacy or other cryptographic methods.
Finally, performance bottlenecks remain a challenge in tokenization workflows. For instance, in [26], although tokenization significantly improved accuracy in emotion recognition, the computational demands associated with processing large healthcare datasets led to delays and inefficiencies. These bottlenecks suggest that while tokenization improves accuracy, its computational complexity can limit its real-world application in resource-constrained environments. The Table 3, summary table of the findings from the literature review:
Table 3 This table provides a concise overview of the main challenges and limitations found in the literature on tokenization in healthcare data analysis
Comments (0)