Deep learning algorithm
The deep learning algorithm used in this study, JLK-ICH, is described in detail elsewhere [8]. Briefly, we trained five U-Net-based segmentation models: lesion segmentation, lesion subtyping and segmentation, SDH classification and segmentation, SAH classification and segmentation, and small lesion (≤ 5 mL) classification and segmentation. The training dataset for SDH, SAH, and small lesions included only SDH, SAH, small lesions, and normal cases. Each ensemble base model was developed using a 2D U-Net with the Inception module. The model was trained to select weight values that minimized the Dice loss between the predicted segmentation at a pixel probability threshold of 0.5 and the ground-truth segmentation.
Study population
For the pivotal clinical trial, we included CT scans of patients with ICH, aged 20 to 95 years, whose radiology reports documented ICH at Seoul National University Bundang Hospital between January 2017 and December 2021. CT scans without ICH were also collected from the same hospital during this period. Scans were excluded if there were errors in the DICOM storage format, significant metallic artifacts, bleeding extending into the extracranial space, or if patient information, such as age, sex, acquisition date, or CT image sequence, was unclear.
For the additional external validation using a multi-ethnic U.S. dataset, we obtained 734 head CT scans from Segmed, Inc. (Stanford, CA, USA) and Gradient Health, Inc. (Durham, NC, USA). These scans were acquired using CT scanners from multiple manufacturers and were accompanied by radiology reports indicating the presence of ICH and its subtypes. The companies removed all protected health information from the scans, reports, and DICOM tags, except for patient age, sex, and ethnicity. Non-contrast CT scans were included if they met the following criteria: patients aged 18 years or older, axial plane acquisition, unenhanced, no motion artifacts, slice thickness greater than 1.5 mm, and use of a standard convolutional kernel.
Sample size estimates
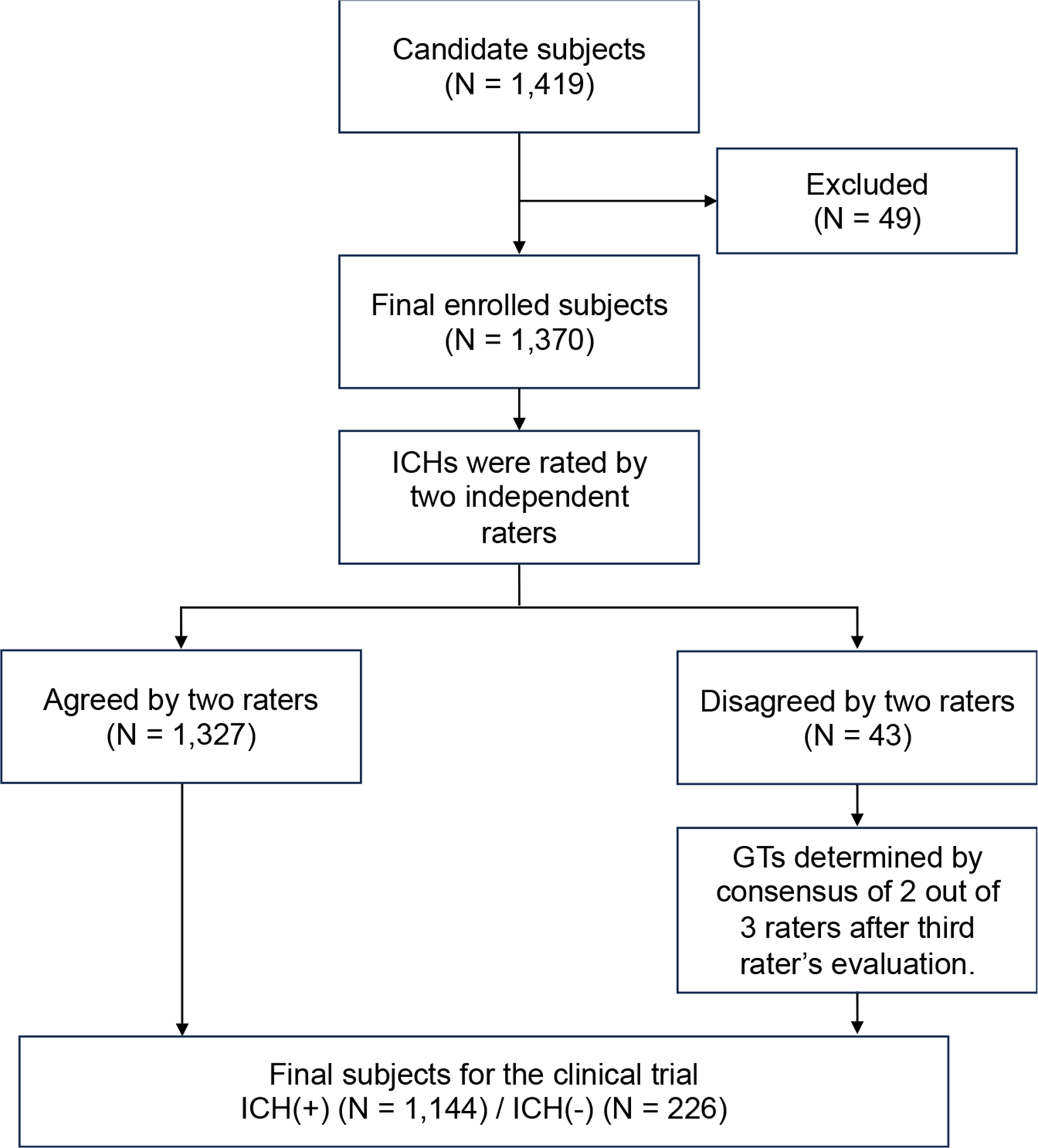
The primary objective was to test whether the sensitivity and specificity of JLK-ICH were comparable to prespecified criteria based on a prior study [9]. For the sensitivity analysis, an ICH-positive sample size of 1,144 patients was estimated to provide 90% power to detect, with a one-sided test at a 2.5% significance level, a prespecified lower bound of 0.8986. For the specificity analysis, an ICH-negative sample size of 226 patients was estimated to provide 90% power to detect, with a one-sided test at a 2.5% significance level and a prespecified lower bound of 0.8148. This sample size accounted for a 1.1% dropout rate.
Evaluation of the diagnostic performance
For the pivotal clinical trial data, all enrolled cases were independently reviewed to establish ground truth by two stroke neurologists with 6–10 years of experience. The presence of each ICH subtype– IPH, IVH, SAH, SDH, EDH– was annotated for each patient. Cases in which the two neurologists disagreed were independently reviewed by a third stroke neurologist with 11 years of experience, and the ground truth was established based on the majority vote of the three experts. For the U.S. dataset for the additional external validation, discordant cases were reviewed and adjudicated by an experienced neuroradiologist with 15 years of experience.
We evaluated the diagnostic performance of the deep learning algorithm for all patients, patients with each ICH subtype (including those with multiple subtypes), and patients with multiple ICH subtypes. In each analysis, the control group consisted of patients without any ICH subtype. We reviewed discrepancies between the deep learning algorithm and the ground truth of the pivotal clinical trial data, identifying false positive (algorithm-positive/ground truth-negative) and false negative (algorithm-negative/ground truth-positive) cases in the pivotal clinical dataset.
Reader performance study
From the entire dataset, 400 CT scans (205 ICH and 195 controls) were randomly selected and assigned to six readers. The six readers included third-year radiology residents (n = 2), a fourth-year emergency medicine resident (n = 1), first- and fourth-year neurosurgery residents (n = 2), and a fourth-year internal medicine resident (n = 1). The readers were blinded to the ground truth and adjudicated the presence of ICH. The 400 scans were divided into two sets of 200 cases each: set A and set B. In the first assessment, three readers reviewed set A unassisted and set B assisted by the deep learning algorithm, while the other three readers reviewed set A assisted and set B unassisted. In assisted cases, both the original CT scans and those with the predicted ICH sites annotated by the deep learning algorithm were used. After a washout period of four weeks, the second assessment was conducted with the roles of the first three and last three readers swapped. Readers were instructed to evaluate each scan by providing two responses: (i) the presence of ICH (yes/no) and (ii) a confidence level on a five-point scale (“no hemorrhage”, “unlikely hemorrhage”, “uncertain”, “likely hemorrhage”, and “hemorrhage”). Even “uncertain” was selected as the confidence level, readers were still required to decide on the presence or absence of ICH.
Statistical analysis
We analyzed the performance of the deep learning algorithm, including the area under the receiver operating characteristic curve (AUROC), sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), and accuracy for all cases and for ICH subtypes: IPH, IVH, SAH, SDH, and EDH. In the reader performance study, we analyzed differences in sensitivity and specificity between deep learning algorithm-assisted and unassisted cases using the Obuchowski-Rockette method for multi reader multicase (MRMC) studies, along with the MRMCaov library [10].






Comments (0)