
Remember me
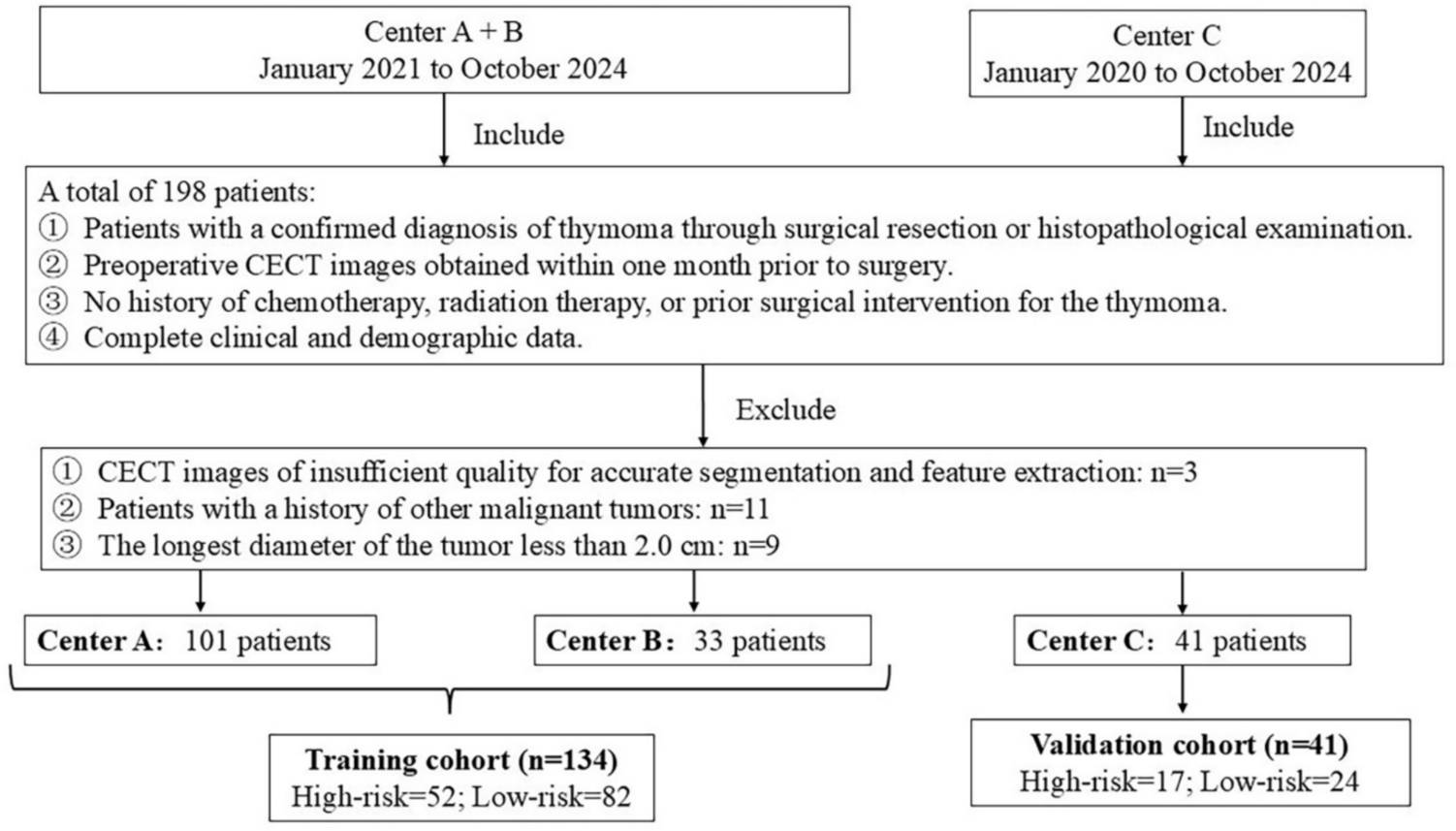
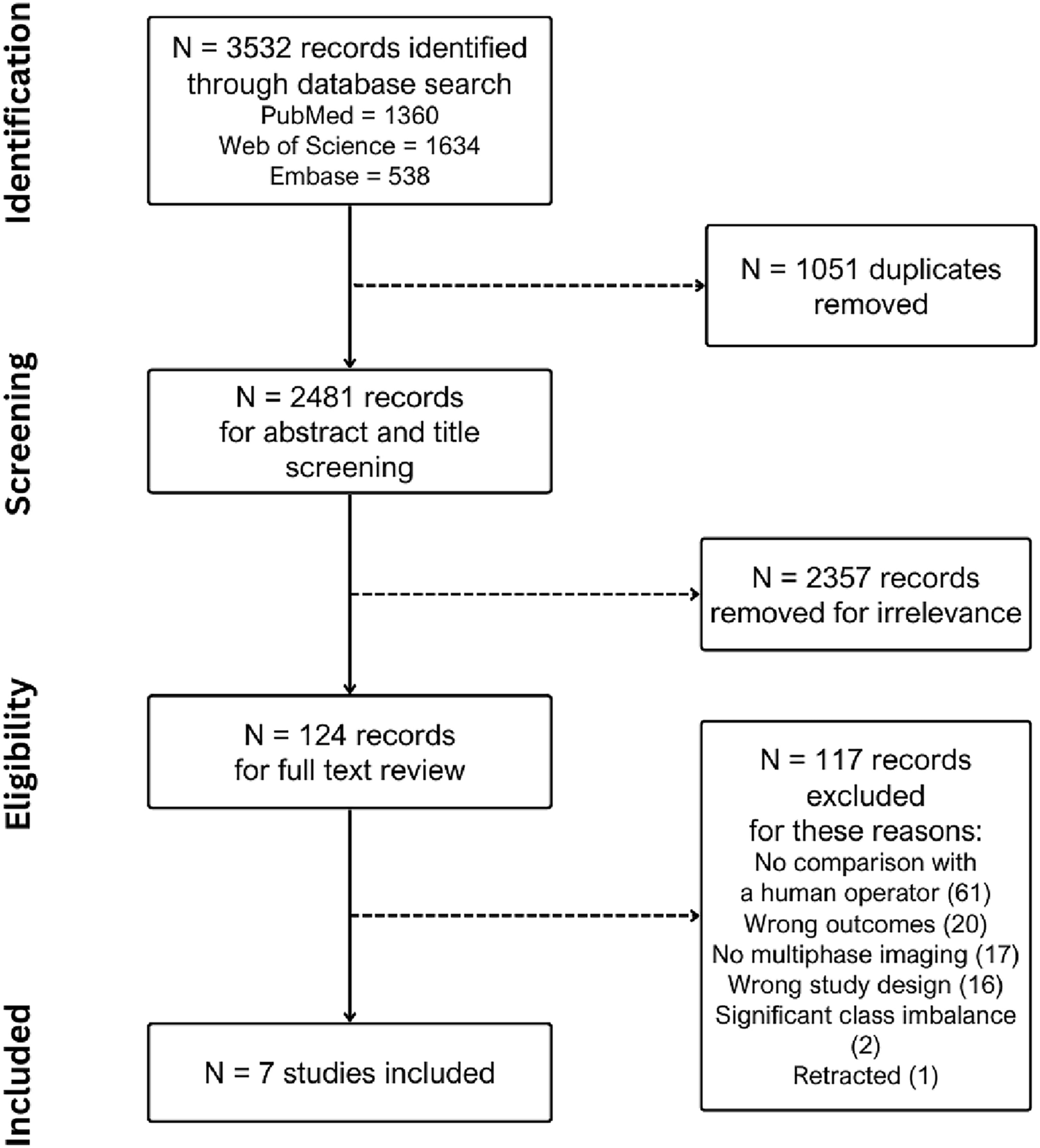

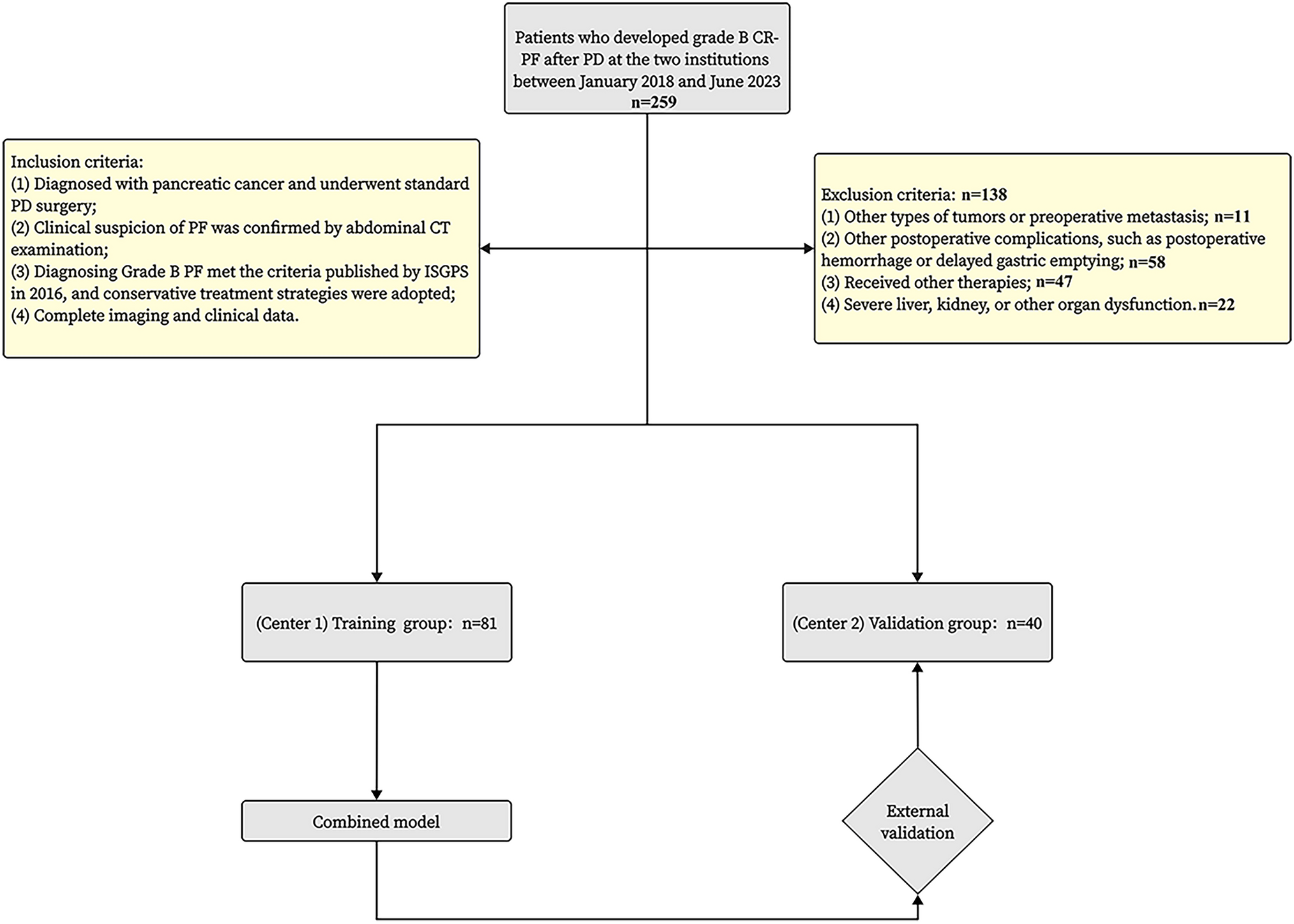
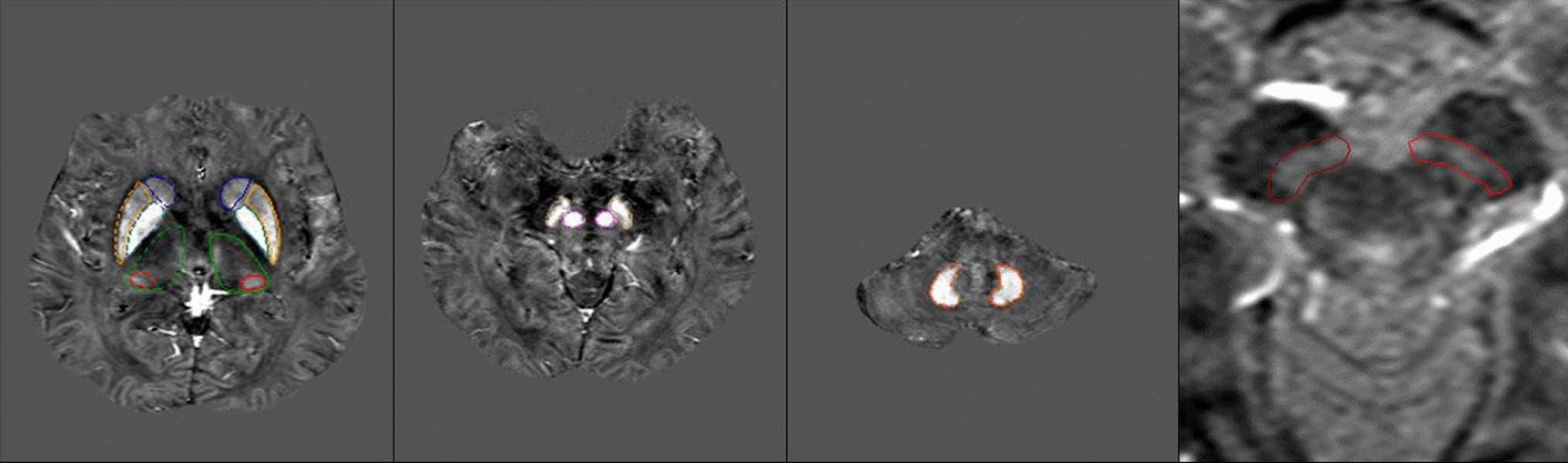


Assessing GPT-4’s performance on all 146 questions of the original Japanese version revealed a median number of correct responses (i.e., scores) of 70 (IQR 68–72). For the English translations by GPT-4, the median score (IQR) was higher, at 89 (84.5–91.5). The scores for the Chinese and German versions translated by GPT-4 were lower, with medians of 64 (IQR 55.5–67) and 56 (IQR 46.5–67.5), respectively. One-way ANOVA with Bonferroni post hoc tests indicated significant differences among the language scores. Specifically, GPT-4’s performance was significantly higher in English than in Japanese (adjusted p-value = 0.002). There was no significant difference between Japanese and Chinese (adjusted p-value = 0.227), but the Japanese scores were significantly higher than those for German (adjusted p-value = 0.022) (Table 1).
Table 1 Number of correct responses by language and year. The p-values were calculated by comparing the number of correct responses for questions in Japanese with those for questions in English, Chinese, and GermanThe Sankey diagrams illustrated the disparities in the counts of correct responses for each question out of five attempts (i.e., points [range: 0–5]) between the original Japanese and translated versions, showing significant variations in points (Fig. 1). These variations were particularly pronounced between the original Japanese and translated English versions. In the translation from Japanese to English, there was an increase in the number of questions with positive changes in points (≥ 4 points). However, this trend was reversed for the Chinese and German translations. The number of questions with positive changes in points ≥ 4 (from 0 to 4, 0 to 5, and 1 to 5) or negative changes in points ≤ –4 (from 4 to 0, 5 to 0, and 5 to 1) were 21 and 3 for English, 4 and 7 for Chinese, and 7 and 10 for German, respectively.
Fig. 1
Sankey diagrams to show the differences in the count of correct responses out of five attempts (i.e., points) for each question between Japanese and the three languages used as prompts. Green nodes represent questions that earned 5 points; light green nodes, 4 points; yellow nodes, 3 or 2 points; and red nodes, 1 or 0 point
Regarding response consistency, GPT-4 selected the same answer(s) across all five attempts for 66 questions in Japanese, 84 in English, 43 in Chinese, and 36 in German out of 146 diagnostic radiology questions. On average, GPT-4 selected the same answer(s) 3.98, 4.34, 3.78, and 3.44 times in Japanese, English, Chinese, and German, respectively. In some instances, GPT-4 consistently selected the same incorrect answer(s) (Table S1), whereas in other cases, incorrect answers varied across attempts (Table S2).
Distribution of accuracy by examination year across the four languagesThis study categorized the 146 questions according to the year in which they were administered. To compare GPT-4’s accuracy across languages, the proportion of correct responses was calculated for each year (i.e., the score divided by the total number of questions for each respective year). Proportions, rather than raw scores, were used to construct scatterplots because the total number of questions varied across different examination years: 42 in 2020, 52 in 2021, and 52 in 2022. The scatterplots revealed variability in the proportion of correct responses per language per year. The order of accuracy, shown by the median proportions, from the highest to the lowest was English, Japanese, Chinese, and German in each year of 2020, 2021, and 2022, and over the 3-year period (Fig. 2).
Fig. 2
Yearly fluctuations in the proportions of correct responses (%) in five attempts by language. Panel (a) illustrates the proportion of correct responses, expressed as a percentage, for an aggregate of 146 Japanese Radiology Board Examination (JRBE) questions from 2020 to 2022. Panels (b–d) represent the proportions of correct responses for subsets of 52 questions from JRBE 2022, 52 questions from JRBE 2021, and 42 questions from JRBE 2020. Each plot depicts the scores for individual attempts, whereas the corresponding bars represent the median score derived from five attempts for the original Japanese and each translated version
Comparison of domain-specific performanceThe 146 diagnostic radiology questions tested in this study included the following domains: musculoskeletal (n = 13), head and neck (n = 9), neuro (n = 18), chest (n = 28), cardiovascular (n = 15), breast (n = 9), gastrointestinal (n = 23), genitourinary (n = 25), and others (n = 6). There were significant differences in the scores (median [IQR]) between the original Japanese (J) and English translations by GPT-4 (E) in several domains: head and neck (J 6 [6–6.5], E [7–7], p = 0.048), neuro (J 11 [10.5–12.5], E 13 [12.5–13.5], p = 0.119), chest (J 13 [12.5–15], E 17 [14.5–17.5], p = 0.048), cardiovascular (J 9 [8–9], E 13 [12.5–14], p = 0.008), gastrointestinal (J 12 [11.5–13], E 15 [13.5–15], p = 0.02), and genitourinary (J 7 [5.5–8], E 14 [13, 14], p = 0.008) domains (Table 2). In contrast to the trends observed in other domains, the musculoskeletal, neuro and breast domains did not show significant differences in scores between the original Japanese and English translations by GPT-4.
Table 2 Comparison of numbers of correct responses (scores) in each attempt for the original Japanese questions and the English translations by Generated Pre-trained Transformer-4 (GPT-4)Level of thinking and question pattern comparisonOf the 146 questions, 99 were categorized as higher-order, requiring application, analysis, or evaluation, whereas the remaining 47 were categorized as lower-order, requiring recall or basic understanding. Significant differences in scores (median [IQR]) were observed between the original Japanese and English translations by GPT-4 in both categories of level of thinking: higher-order (J 45 [43.5–47.5], E 60 [56–60.5], p = 0.008) and lower-order (J 24 [23.5–26], E 31 [27–31.5], p = 0.02) (Table 2).
Questions were also categorized by pattern: two-answer (n = 42) and one-answer (n = 104). Significant differences in the scores were observed between the two language versions: two-answer (J 14 [13–18.5], E 21 [18.5–23], p = 0.008) and one-answer (J 55 [54.5–57.5], E 66 [64.5–71], p = 0.008) (Table 2).
Effects of translation quality on GPT-4’s performance in each languageFor DeepL translations, the median score was 62 (IQR: 57.5–64.5), significantly lower than the score for GPT-4 translations, which was 89 (IQR: 84.5–91.5) (p = 0.0079). The average translation grade for DeepL English translations was 2.64, significantly lower than the grade for GPT-4 translations, which was 3.12 (p < 0.0001).
Linear regression analyses showed that higher grades in translation quality were significantly associated with an increased counts of correct responses across five attempts in both the GPT-4-English, DeepL-English, and GPT-4-German versions (GPT-4: slope = 0.058, p = 0.003; DeepL: slope = 0.128, p < 0.0001; German: slope = 0.110, p < 0.0001). In contrast, for the GPT-4 Chinese translations, linear regression analyses did not reveal significant associations between translation quality and performance (slope = -0.005, p = 0.82) (Table 3).
Table 3 Effect of translation quality on GPT-4’s performance in each languageComparison of GPT-4's Performance on English Versions Translated by GPT-4 and by a professional serviceThe professional translations did not differ significantly from the GPT-4 translations (90, IQR: 89.5–91.0 vs. 89, IQR: 84.5–91.5) (p = 0.627) (Fig. 3a). However, a subgroup analysis of 31 questions where GPT-4’s responses to the original Japanese outperformed the English translations by GPT-4, revealed improved scores (median [IQR]) when using professionally translated questions (13 [12.0–14.0]), compared with when using GPT-4-translated questions (8 [5–9.5], p = 0.0079) (Fig. 3b). The topics of thequestions in this subset and counts of correct responses from GPT-4 across the five attempts for each question (i.e., points [range, 0–5]) are detailed in Table 4. The Sankey diagram illustrates point shifts for each question across the English version translated by GPT-4, English version translated by a professional service, and the original Japanese questions (Fig. 4). A significant increase in points from English translation by GPT-4 to professional translation was observed: a 5-point increase in 2 questions, 4-point increase in 3 questions, 3-point increase in 4 questions, 2-point increase in 0 question, and 1-point increase in 7 questions. No increase or decrease in points were observed in 10 and 5 questions, respectively.
Fig. 3
Comparison of Generative Pre-trained Transformer (GPT)-4’s scores in questions translated into English by the professional translation service compared with those translated by GPT-4. Each plot depicts the scores for each attempt, with the corresponding bars representing the median score derived from five attempts for each translation method. Panel (a) shows the scores for the entire set of 146 questions, whereas panel (b) focuses on the subset of 31 questions where GPT-4’s responses to the original Japanese questions outperformed those to the GPT-4English translations. Abbreviations: Jp Japanese, En English, ns not significant
Table 4 Detailed analysis results for a subset of 31 questions where GPT-4’s responses to the original Japanese outperformed the English translations generated by GPT-4Fig. 4
Sankey diagrams to show the differences in the count of correct responses out of five attempts (i.e., points) for each selected question among English translations by GPT-4 and professional English translation and those in Japanese. Green nodes represent questions that earned 5 points; light green nodes, 4 points; yellow nodes, 3 or 2 points; and red nodes, 1 or 0 point
Comments (0)