
Remember me


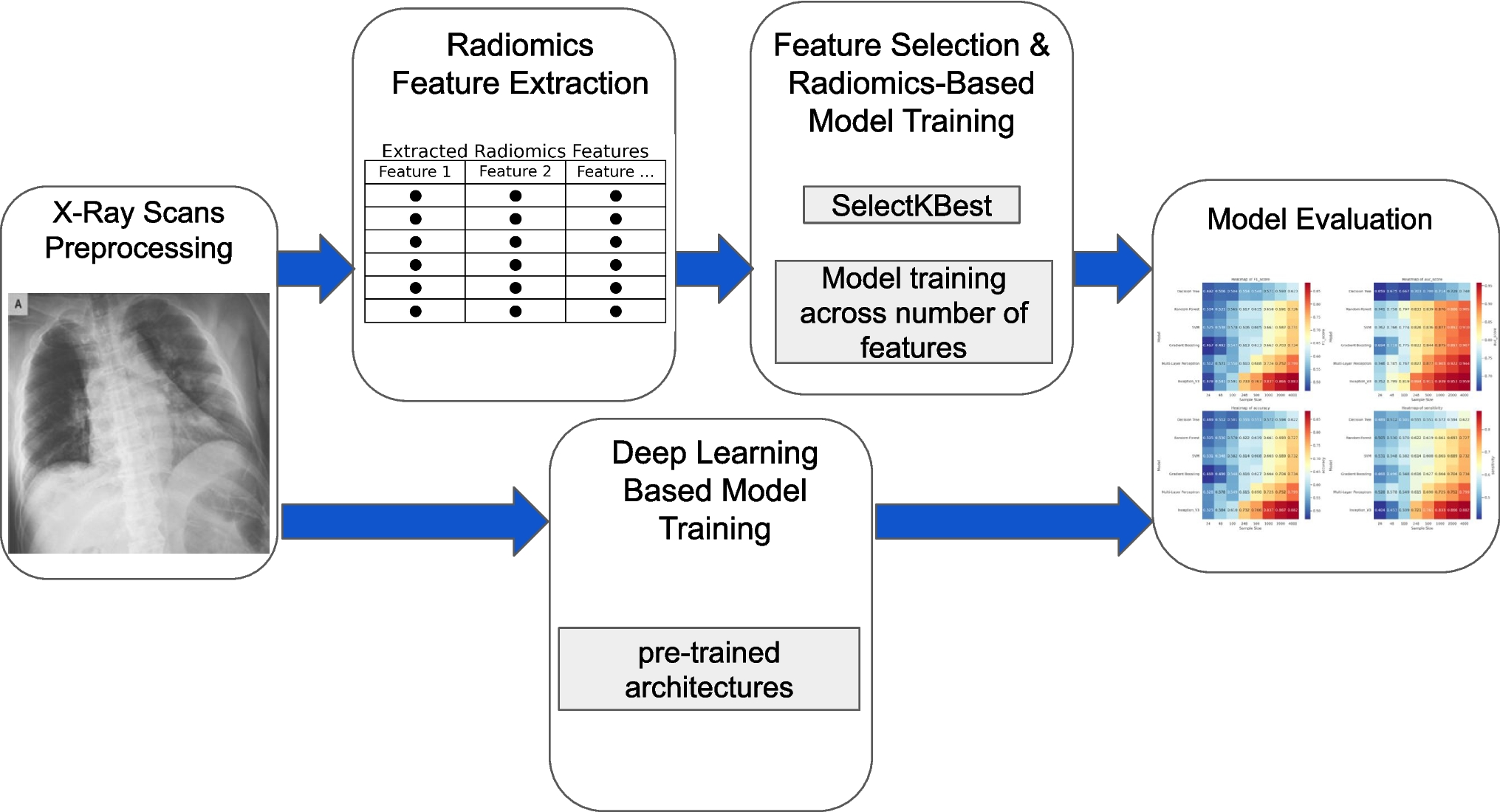
This study followed a multi-stage pipeline involving radiomics feature extraction and data preprocessing, model training, and evaluation. The workflow integrated both radiomics-based and deep learning-based approaches for multi-class classification of chest X-ray images. A visual overview of the methodology is provided in Fig. 1.
Fig. 1
Overview of workflow for this study. The workflow integrates radiomics and deep learning for X-ray analysis. It starts with X-ray preprocessing, followed by radiomics feature extraction. Feature selection (SelectKBest) and model training are performed, while deep learning models are trained separately. Finally, both approaches undergo model evaluation using performance metrics
Data SourceThis study utilized a publicly available and comprehensive dataset of chest X-ray images, sourced from multiple repositories and compiled by a team of international researchers [26]. The dataset contains a total of 21,165 images categorized into four classes: 3616 images of patients diagnosed with COVID-19, 6,012 images of patients with lung opacity, 1345 images of patients with viral pneumonia, and 10,192 images of patients with no disease findings (Normal). The dataset is in the Portable Network Graphics (PNG) format with a resolution of 299 × 299 pixels and includes a posteroanterior view chest radiograph and its corresponding lung segmentation masks.
The full aggregated dataset was partitioned into training, validation, and testing subsets. A total of 344 samples per class were reserved for the test set using stratified sampling to ensure balanced representation across all four categories. This number was chosen based on the smallest class size (1345 samples), allowing up to 1000 samples to remain available for training. The remaining data was used to create training subsets of varying sizes (24, 48, 100, 248, 500, 1000, 2000, and 4000) using stratified sampling to preserve class distribution. A fivefold cross-validation strategy was employed, with each fold further split into 80% training and 20% validation.
Radiomics Feature Extraction and PreprocessingA pipeline was employed to prepare medical images and their corresponding lung segmentation masks for radiomics feature extraction, ensuring standardized model inputs. File paths were generated for each subject, systematically organizing image and mask files based on predefined directory structures. Using the SimpleITK [27] library, images and Masks were loaded, converted to grayscale if necessary, and rescaled to an intensity range of 0 to 255 using the RescaleIntensityImageFilter. Both images and Masks were cast to 8-bit unsigned integers to ensure compatibility with subsequent radiomics feature extraction processes. The mask was resampled to match the image size and spatial resolution using nearest-neighbor interpolation, ensuring consistent spatial dimensions and intensity values across inputs.
Radiomic features were extracted using PyRadiomics [28], encompassing both texture-based and intensity-based descriptors. To identify the most informative features for classification, we applied the SelectKBest method from Scikit-learn [29], which ranks features based on the F-values derived from Analysis of Variance (ANOVA). Features such as Gray Level Co-occurrence Matrix (GLCM) Cluster Shade and Cluster Tendency (which quantify texture heterogeneity), along with First-order Skewness and Interquartile Range (which describe intensity distribution), were among the highest-ranked based on their ANOVA F-scores. The data was normalized, and reference standard annotations (0 for normal, 1 for COVID, 2 for viral pneumonia, and 3 for lung opacity) were assigned to each class.
Deep Learning-Based Model Data PreprocessingFor the image-based deep learning models, the data was preprocessed to match the input format required by the models. Images were resized to 256× 256 pixels, and pixel values were normalized to the [0, 1] range. Data augmentation was performed using TensorFlow [30]'s ImageDataGenerator, including rescaling, shear transformations, zoom operations, and horizontal flipping to simulate variability in chest X-ray images. This preprocessing ensured that model inputs were consistent with the preprocessed image format and enhanced the model’s generalization capabilities. The images were organized into directory structures for efficient loading via the flow_from_directory method.
Radiomics-Based Model TrainingFor radiomics-based classification, both traditional machine learning algorithms and a deep learning model were implemented to evaluate performance on handcrafted feature sets. Traditional classifiers included SVM, Decision Trees, Gradient Boosting, and Random Forests, all developed using Scikit-Learn. Input features were standardized using the StandardScaler, and dimensionality reduction was performed using the SelectKBest method with ANOVA F-value (f_classif) as the scoring function. For each model, subsets of the top k features (ranging from 1 to the total number of extracted features) were evaluated to identify the configuration that yielded the highest performance. The SVM classifier (SVC) was configured with probability = True and used the default RBF kernel (C = 1.0, gamma = ‘scale’). Decision Tree, Gradient Boosting, and Random Forest classifiers were used with default hyperparameters. In addition to these traditional models, a deep learning-based MLP was implemented using Keras/TensorFlow to assess the suitability of neural architectures for radiomics data. The MLP architecture consisted of a 64-unit dense layer, followed by a dropout layer (dropout rate = 0.2), a 32-unit dense layer, and a final softmax output layer for multi-class classification. The MLP was trained for 100 epochs, consistent with common deep learning training practices. For reproducibility, we fixed the random seed for the subset sampling process, cross-validation, and for the fold shuffling in StratifiedKFold (random_state = 42 in both cases) to control key sources of randomness. For each model, the configuration yielding the maximum F1 score across all k-feature evaluations was retained for comparative analysis.
Deep Learning-Based Model TrainingImage-based deep learning models, including ConvNeXtXLarge, EfficientNetL, and InceptionV3, were employed. These models utilized architectures pre-trained on ImageNet, with their base weights fine-tuned end-to-end for the specific classification task. TensorFlow/Keras [31] was used to build sequential models, with a consistent classification head added to each base network. This included a global average pooling layer, a 256-unit dense layer with ReLU activation, batch normalization, a 0.5 dropout layer to prevent overfitting, and a final softmax output layer to produce class probabilities for multi-class classification. All deep learning-based models were trained using the Adam optimizer with a learning rate of 0.0001 and a batch size of 16. Training was conducted for 100 epochs without learning rate scheduling or early stopping, in order to ensure comparability across models. The loss function used was categorical cross-entropy. Identical subsets and dataset selection were used for both Radiomics-based and Deep Learning-based model training, as described above.
Model Outputs and EvaluationThe outputs of both the radiomics-based and image-based models were designed to predict the likelihood of each class (normal, COVID-19, viral pneumonia, and lung opacity), in line with the clinical requirement for multi-class classification of chest X-ray images. Model performance was assessed using the weights from the best-performing epoch on the validation set for each training fold. Performance metrics such as F1 score, AUC score, accuracy, sensitivity, and specificity, which were averaged across folds and runs, provide a comprehensive assessment of model performance.
The performance of various models across different sample sizes was rigorously analyzed to identify statistically significant differences in these five key metrics. A non-parametric Scheirer-Ray-Hare (SRH) test was employed to provide a statistical understanding of the effect of model selection and sample size [32]. This test, fundamentally an ANOVA performed on ranks, was implemented by converting the original scores for each metric into their respective ranks before applying a standard two-way ANOVA. Furthermore, pairwise Mann–Whitney U tests were conducted to determine specific group differences. For sample size comparisons, performance scores were aggregated across all models within each sample size group to assess the overall effect of data quantity. Conversely, for model comparisons, results were aggregated across all sample sizes to evaluate average model superiority. To mitigate the risk of Type I errors arising from multiple comparisons, p-values from these pairwise tests were adjusted using the Bonferroni correction.
Radiomics-based model training was conducted using Python 3.10.12 with the following libraries and versions: imbalanced-learn 0.13.0, scikit-learn 1.5.2, pandas 2.2.2, NumPy 2.0.2, and TensorFlow 2.17.0. Deep learning-based model training was performed using Python 3.9.23 with the following libraries and versions: scikit-learn 1.6.1, NumPy 2.0.2, SciPy 1.13.1, TensorFlow 2.17.0, joblib 1.4.2, and threadpoolctl 3.5.0. Statistical analyses were conducted using statsmodels 0.14.5 and pingouin 0.5.5. Figures and tables were produced using pandas 2.2.2, Matplotlib 3.8.4, and Seaborn 0.13.2.
Comments (0)