How Well Do ChatGPT and Claude Perform in Study Selection for Systematic Review in Obstetrics
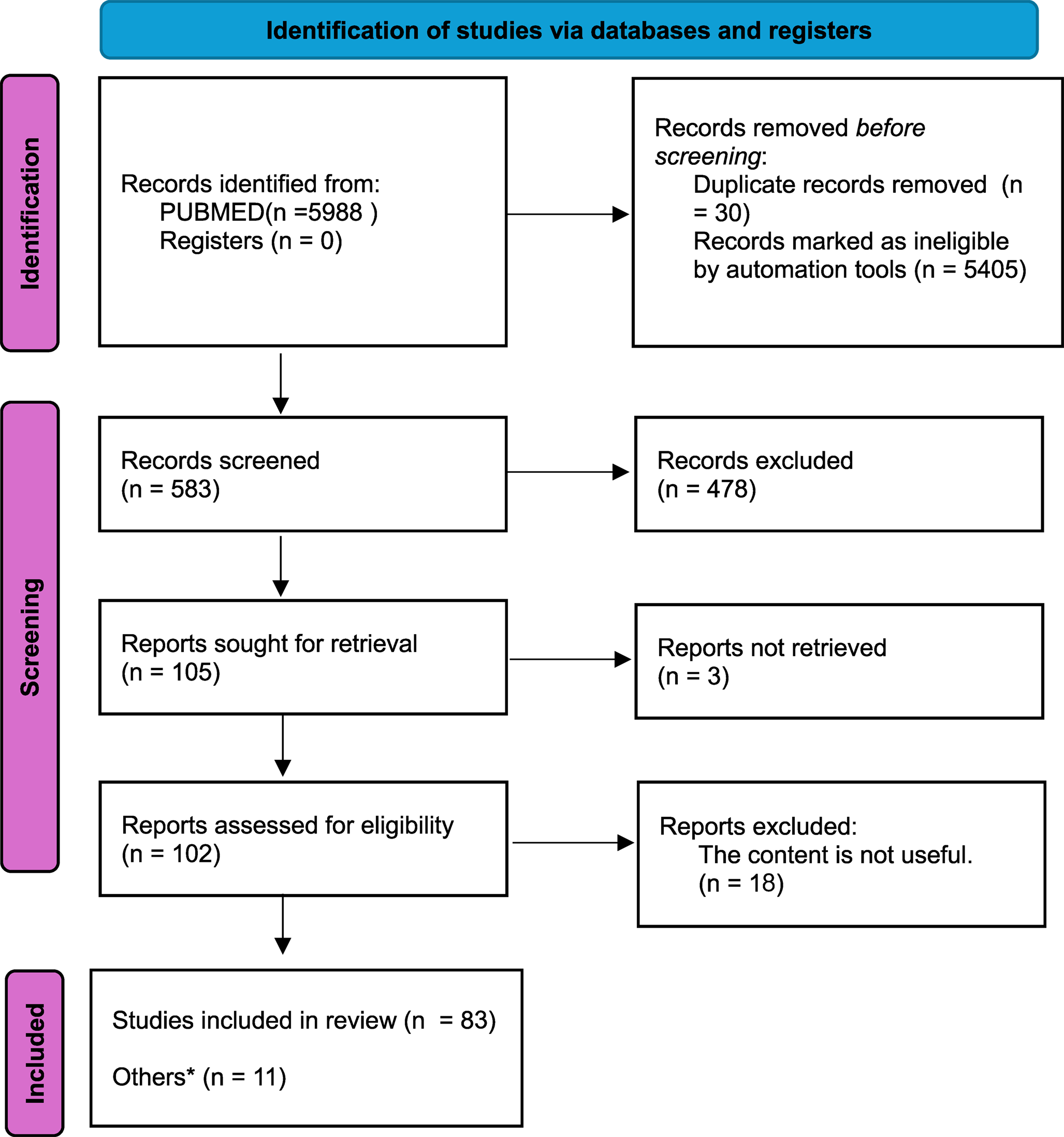
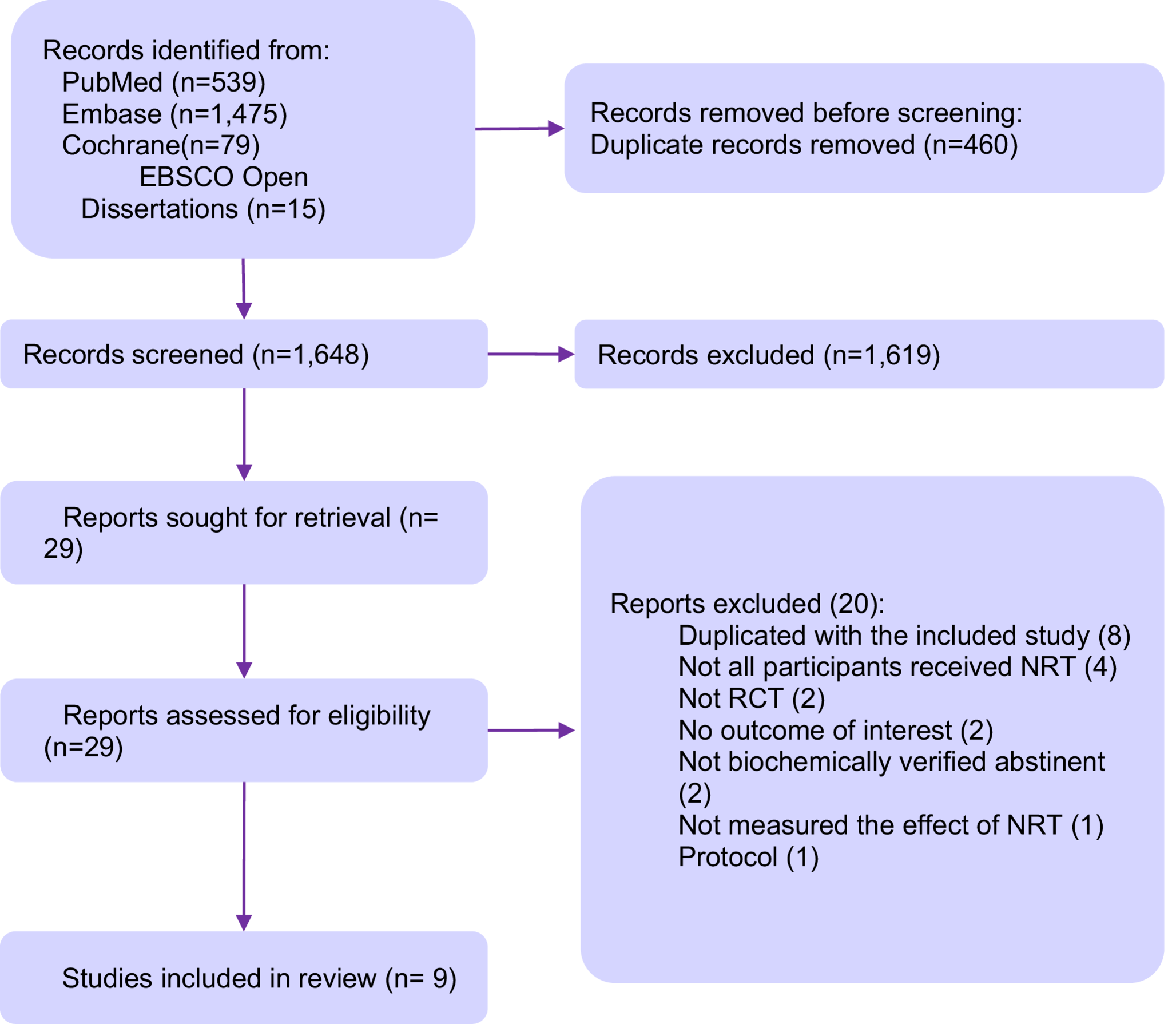
The use of generative AI in systematic review workflows has gained attention for enhancing study selection efficiency. However, evidence on its screening performance remains inconclusive, and direct comparisons between different generative AI models are still limited. The objective of this study is to evaluate the performance of ChatGPT-4o and Claude 3.5 Sonnet in the study selection process of a systematic review in obstetrics. A literature search was conducted using PubMed, EMBASE, Cochrane CENTRAL, and EBSCO Open Dissertations from inception till February 2024. Titles and abstracts were screened using a structured prompt-based approach, comparing decisions by ChatGPT, Claude and junior researchers with decisions by an experienced researcher serving as the reference standard. For the full-text review, short and long prompt strategies were applied. We reported title/abstract screening and full-text review performances using accuracy, sensitivity (recall), precision, F1-score, and negative predictive value. In the title/abstract screening phase, human researchers demonstrated the highest accuracy (0.9593), followed by Claude (0.9448) and ChatGPT (0.9138). The F1-score was the highest among human researchers (0.3853), followed by Claude (0.3724) and ChatGPT (0.2755). Negative predictive value (NPV) was high across all screeners: ChatGPT (0.9959), Claude (0.9961), and human researchers (0.9924). In the full-text screening phase, ChatGPT with a short prompt achieved the highest accuracy (0.904), highest F1-score (0.90), and NPV of 1.00, surpassing the performance of Claude and human researchers. Generative AI models perform close to human levels in study selection, as evidenced in obstetrics. Further research should explore their integration into evidence synthesis across different fields.




Comments (0)