In this section, I describe the methodological approach adopted for transforming bioethical discourse into structured matrices to enable a systematic, quantitative analysis. This approach helps reveal underlying linguistic structures and patterns, providing insights into how different levels of language precision affect ethical deliberation. The methodology involves constructing bioethical vignettes, converting them into semantic matrices, and using advanced visualization techniques to interpret the data.
Bioethical Vignettes and Colexification
The core data source for this study is a set of bioethical vignettes,Footnote 5 each addressing significant topics within the domain, such as end-of-life care, informed consent, and organ donation. Each vignette was prepared in two distinct versions: High Colexification (HC) and Low Colexification (LC). The HC versions use language that allows multiple meanings for some words, inherently leading to a broader, often ambiguous interpretation. On the other hand, the LC versions strive for linguistic specificity, minimizing the use of ambiguous terms to ensure a more precise, focused discussion. For vignettes and their various versions, please refer to the online supplementary material linked to this article.
The goal of creating both HC and LC versions was to investigate how language precision impacts the structure and interpretation of bioethical discourse. This distinction allowed us to directly assess the influence of colexification on ethical decision-making and the coherence of the discourse, focusing on how these different levels of linguistic specificity affected the relationships between key concepts. To analyse the linguistic content of the vignettes, I constructed semantic distance matrices using Word2Vec word embeddings. This approach allowed me to quantify the relationships between key terms within the vignettes, based on their semantic similarities or differences. Broadly, Word2Vec operates as a shallow neural network that learns distributed representations by predicting neighbouring words within a context window (Mikolov, et al. 2013). Through this process, words frequently co-occurring in similar linguistic environments converge in vector space, reflecting semantic affinity. In practical terms, each token is transformed into a numeric vector whose dimensions capture latent semantic features, thus enabling the calculation of similarities (or dissimilarities) among tokens. This methodology, widely used in modern NLP pipelines, allows for flexible modelling of lexical meaning in large corpora and stands as one of the standard approaches for vectorizing textual data in empirical studies.
Matrix Construction and Semantic Distance
The transformation of bioethical vignettes into structured matrices involved the creation of semantic distance matrices that represent the relationships between words based on their meanings. This process was carried out using word embeddings derived from a pre-trained Word2Vec model (The TensorFlow Authors 2020). The following steps detail the construction of these matrices: A) Tokenization: Each vignette was tokenized into individual words, allowing for a breakdown of the language into discrete components. Each token represented a key term or phrase relevant to the bioethical context presented in the vignette. B) Word Embedding Generation: Using Word2Vec, each token was converted into a high-dimensional vector. Word2Vec is capable of capturing the contextual meaning of words by analysing large corpora of text. The resulting vectors represent semantic properties of the words and their relationships within the corpus used to train the model. C) Calculation of Semantic Distances: Once the word embeddings were generated, the next step involved calculating the semantic distance between each pair of words. This was accomplished using cosine similarity, a common metric used in natural language processing to measure the closeness between two vectors. Cosine similarity values were transformed into distance values (1 - cosine similarity) to construct a symmetric matrix representing the semantic relationships within each vignette. D) Matrix Representation: The resulting semantic distance matrices were formatted to reflect the relationships between all key terms within each vignette. For HC vignettes, the matrices tended to have greater distances between certain key terms, reflecting the ambiguity and variability in meaning caused by colexification. Conversely, LC matrices exhibited smaller semantic distances, indicating more direct and less ambiguous relationships between terms.
$$CosineSimilarity=\frac$$
Where:
A and B represent the vector embeddings of two words.
||A|| and ||B|| are the magnitudes of the vectors.
The cosine similarity values range from −1 to 1, where a value close to 1 indicates high semantic similarity, while a value closer to 0 or negative indicates low or opposite similarity. To construct the semantic distance matrices, I converted the cosine similarity scores into semantic distances. This was done using the formula:
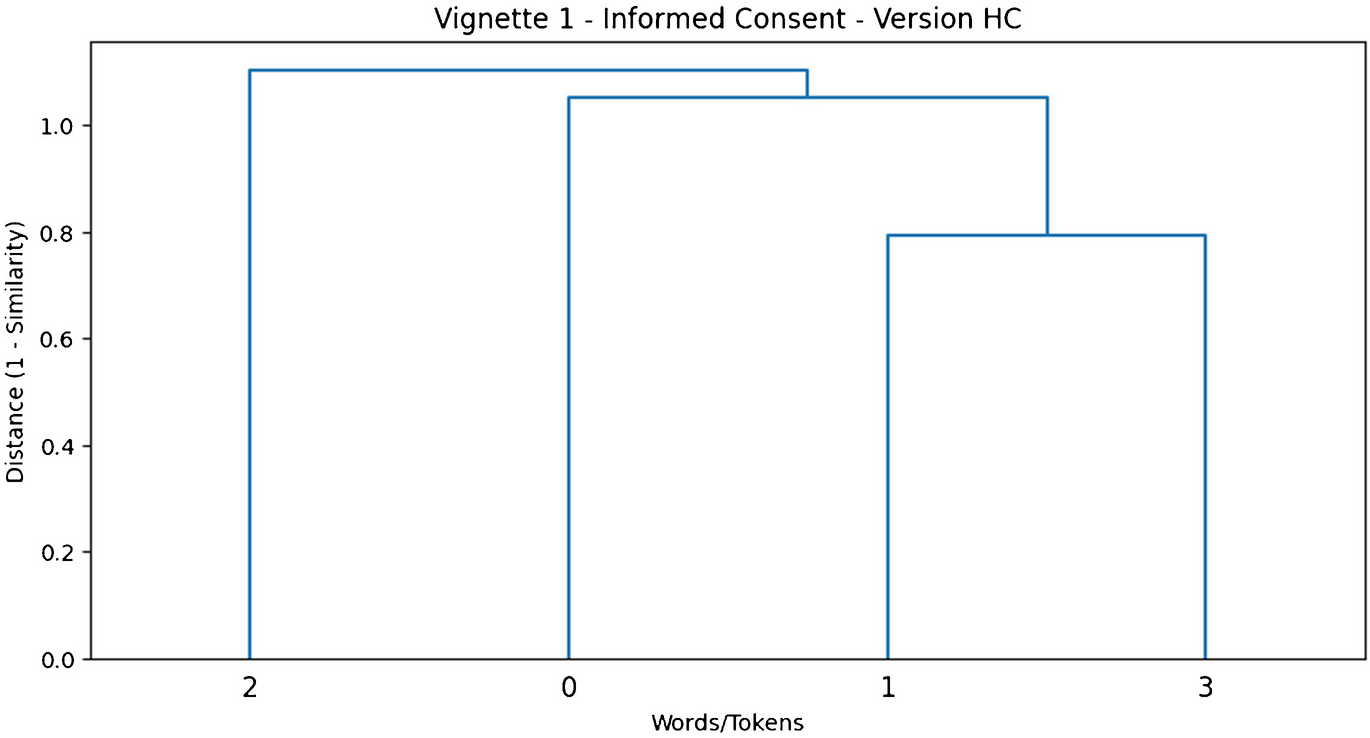
This transformation makes the interpretation of relationships more straightforward: a lower distance indicates a close semantic relationship, whereas a higher distance indicates greater dissimilarity. Using these distance values, I constructed matrices for each vignette version. The LLM-derived embeddings enabled a more accurate representation of the relationships between key terms, especially when dealing with highly ambiguous or context-sensitive language. The resulting matrices provide a systematic way to analyse linguistic ambiguity and colexification across different bioethical contexts. Let’s work with the two versions of Vignette 1 (“Informed Consent in Medical Procedures”) as an example, detailing the encoding for both the High Colexification (HC) version and the Low Colexification (LC) version.
Definition of the word vector:
HC Version:
Relevant words: [“treatment”, “improve”, “condition”, “options”, “clear”, “decide”, “plan”, “suggested”]
These words have a degree of ambiguity, as each can refer to different aspects without much specificity.
LC Version:
Relevant words: [“surgery”, “replacement”, “hip”, “osteoarthritis”, “risks”, “benefits”, “infection”, “clots”, “recovery”]
These words are more specific and provide details that reduce the ambiguity of the dilemma
Assignment of numerical values:
A matrix is created in which each row and column represents a word, and the value within the matrix represents the semantic distance between those two words. These values are computed using a combination of methods, including semantic embedding spaces to quantify similarity, co-occurrence frequency from relevant corpora, and manual assessment of conceptual proximity. The resulting distances reflect how closely related the meanings of the words are within the context of the vignette. In the context of the Word2Vec model used (Mikolov et al. 2013), the numerical values in the matrices are derived based on how Word2Vec represents words in a high-dimensional embedding space. Here’s a detailed explanation of how this works and how the values are assigned to tokens. Word2Vec is a neural network-based model that converts words into dense numerical vectors of fixed dimensions, often called word embeddings. I used the Google Collaboratory Notebook by The TensorFlow Authors (2020). Each word is represented as a vector of real numbers (e.g., in a 100-dimensional space). Words with similar meanings are placed close together in this high-dimensional space. These vectors capture semantic information—words that have similar meanings or that are used in similar contexts will have similar vectors. I trained the Word2Vec model on a corpus (in this case, the bioethical vignettes), the model learned to assign each word a specific vector based on its contextual usage across the corpus. For instance, if “treatment” often appears in similar contexts as “therapy” Word2Vec will learn to give these two words vectors that are close to each other in the embedding space.
The complete set of cosine similarity matrices, representing both High Colexification (HC) and Low Colexification (LC) versions of the bioethical vignettes, is included within the supplementary materials. While I acknowledge that other approaches, such as the Kullback–Leibler divergence (Kullback and Leibler, 1951), could be employed, I ultimately opted for cosine similarity. In my view, cosine similarity offers a straightforward, well-established procedure for quantifying the angle between normalized vectors (Salton and McGill, 1983, Chowdhury, 2010), which makes it particularly intuitive for characterizing similarities in my dataset. Its ease of interpretation, combined with its broad acceptance in related empirical studies, justifies this methodological choice over other metrics.
In the context of bioethics, you might use these matrices to determine which concepts in a vignette are closely related. For example, high similarity between “treatment” and “consent” could indicate a meaningful semantic relationship relevant to informed consent discussions. The clusters of high similarity values in the matrix can help identify key themes or relationships in the vignette. If several words have high similarities to each other, it suggests a cluster of related concepts. Through the comparison of similarity matrices across various versions of a vignette (such as HC vs. LC), you can observe how word relationships alter with varying levels of detail. For instance, terms pertaining to “risks” and “treatment” may exhibit heightened resemblance in a more comprehensive version, underscoring the significance of furnishing more precise details. The matrices can help ethical analysts understand whether the language used in different scenarios (e.g., medical consent vs. decision making) affects how related concepts (like “patient,” “risk,” and “treatment”) are perceived. It could also be useful for analysing whether certain terms are ambiguous or interpreted differently in different contexts, which is essential for clarity in bioethical communication.




Comments (0)