
Remember me



The experiment conducted in this study was completed using a protocol approved by the University of Rochester Research Subjects Review Board (No. 3866). We recruited 12 (3 males, 9 females) subjects for this study. All subjects provided informed consent prior to participating in the experiment and were compensated for their time. The mean ± SD age of the subjects was 21 ± 4.1 (range 18–34) years. Subjects reported no neurological disorders or abnormalities. Normal hearing thresholds (≤ 20 dB HL) for all subjects were confirmed with pure tone audiometry from 250 to 8000 Hz at octave frequencies. Due to the large number of conditions (20 HPN cutoffs at 3 stimulus rates) and time needed to test each condition (since the derived response technique halves SNR), recordings were split over 4 sessions. Each session contained 150 min of stimuli, providing a total recording time of 600 min per subject and 10 min per condition. Two subjects completed only two of the four sessions, resulting in only 5 min per condition for those subjects.
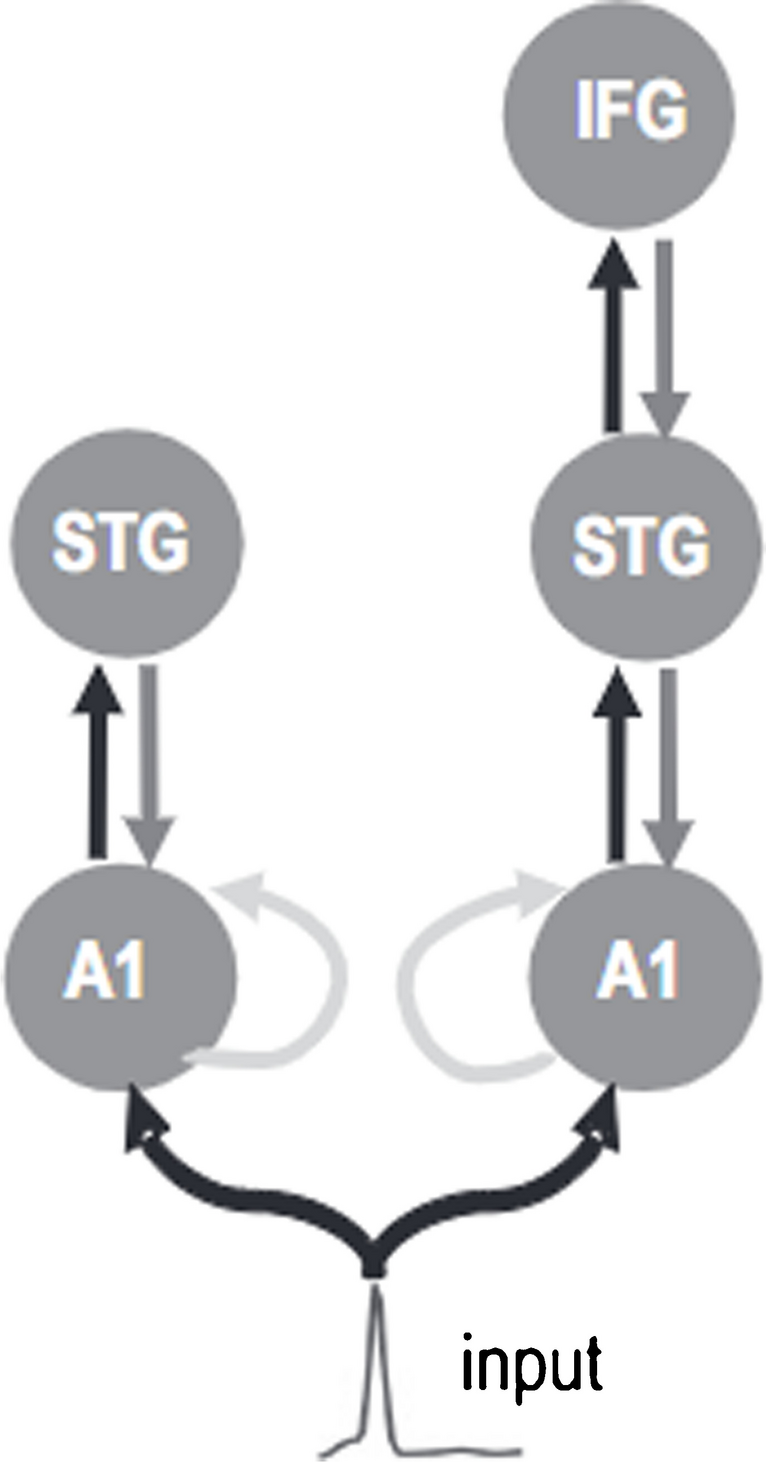
pABR GenerationThe pABR stimuli were constructed as described previously, shown in Fig. 3 [13]. Toneburst trains at five octave-spaced stimulus frequencies (500, 1000, 2000, 4000, and 8000 Hz) were generated with their timing determined by independent random Poisson processes. These toneburst trains were then summed together to produce the stimulus for one ear, and the process was repeated for the other ear. Masking noise (with varying cutoff frequencies) was added to the stimuli (described in more detail below). For both the stimuli and the noise, 60 one-second tokens were generated, and the noise token paired with the stimulus on each trial was randomized.
Fig. 3
Overview of stimulus generation, recording, and analysis techniques. First, tonebursts of five frequencies are convolved with unique impulse trains and summed together. A random half of the impulses were flipped to produce rarefaction and condensation tonebursts. Next, the stimulus is presented to the subject while recording EEG. Then, the impulse trains used in the stimulus generation step are rectified and cross correlated with the corresponding section of EEG to determine the response for each stimulus frequency, and responses from different trials are averaged together. Since the cross-correlation is computed in the frequency domain, the impulse train is padded with zeros on either side, with the bounds of the EEG window expanded to match, prior to any calculations to prevent circular artifacts. The process is shown here for one ear, but the other ear can be measured at the same time using differently timed, independent toneburst trains. From Polonenko and Maddox [13]. Licensed CC BY-NC
Serial stimuli were identical to parallel stimuli, except a single toneburst train was selected to be presented in isolation (i.e., other stimulus frequencies were not included in the stimulus). Only two frequencies (500 Hz and 2000 Hz) were tested for the serial condition due to time constraints during recording. These frequencies were selected because 500 Hz is the lowest commonly used test frequency and expected to have the largest benefit to place specificity from parallel presentation, and 2000 Hz is in the middle of the range of commonly tested frequencies, where we expected less difference in place specificity between parallel and serial conditions.
Three stimulus rates (20, 40, and 100 stim/s) were tested to examine the effect of rate on the strength of masking, with different rates presented in a random order. Rates of 20 and 40 stim/s have previously been shown to be optimal to reduce pABR test times [18], while a higher rate of 100 stim/s was expected to provide additional masking and produce more place-specific responses.
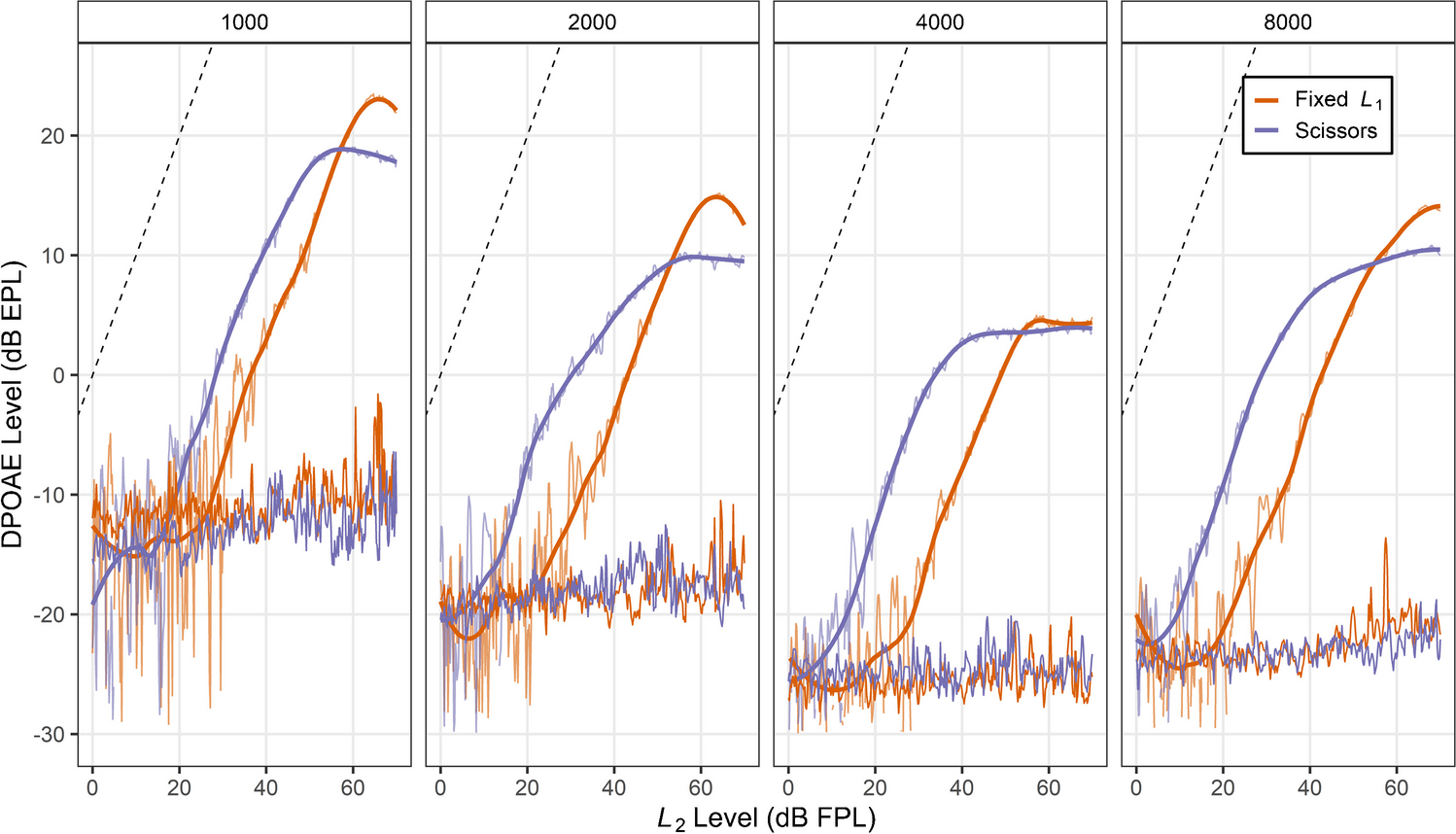
Derived-Band ResponsesDerived-band responses were obtained using methods described in prior studies [15,16,17]. High-pass filtered pink noise was added to both the parallel and serial stimuli, and the cutoff frequency of the high-pass filter was varied in half-octave steps. For parallel stimuli, the HPN cutoff frequency ranged from 250 to 16,000 Hz, resulting in 13 parallel conditions. For serial stimuli, the cutoff frequency ranged from one octave below to two octaves above the test frequency, resulting in 7 serial conditions. Octave-wide derived responses were obtained by subtracting responses which had the HPN cutoff frequency one octave apart. Throughout this study, we take the convention of denoting the octave-wide response band by the frequency in the center of the two high-pass noise cutoffs as determined by the geometric mean (e.g., the derived response band corresponding to the 707 to 1414 Hz region is denoted as 1000 Hz).
Stimulus Presentation and EEG RecordingDuring the experiment, subjects were seated in a comfortable reclining chair in a sound-isolated and electrically shielded room (IAC, North Aurora, IL, USA) and had the option to sleep or watch muted, captioned videos during the experiment. Stimuli were presented using ER-2 insert earphones (ER-2, Etymotic Research, Elk Grove, IL). The toneburst stimuli were presented at 75 dB peSPL. The level from the masking noise was set based on pilot data such that the noise with the lowest cutoff (250 Hz) completely masked the serial responses. Based on pilot data, the masking noise was set to 69 dB SPL, but the level was increased to 72 dB SPL after 6 subjects since responses were not completely masked in all subjects. Masking effects improved, but some subjects still showed responses where they were expected to be masked. In the end, overall results were the same for both masking noise levels, so they are not separated for analysis here.
A Python script was used to control the experiment using open-source software [19]. The Python script sent both the audio stimuli and triggers through a soundcard (Babyface, RME, Haimhausen, Germany) which sent the triggers to a custom trigger box [20] to be passed to the EEG system for precise timing.
EEG was recorded using BrainVision ActiChamp and EP preamps (Brainvision LLC, Greenboro, SC) at a sampling rate of 10 kHz. Passive Ag/AgCl electrodes were used to record responses from FCz (in the standard 10–20 montage) to the right and left earlobe with ground on forehead. The FCz electrode was plugged into a Y-connector to act as the noninverting electrode for both preamps, while the earlobes were used as the inverting electrode.
Response CalculationThe raw EEG recording was bandpass filtered between 30 and 2000 Hz using a causal first-order Butterworth filter and notch filtered at odd integer multiples of 60 up to 2500 Hz using causal IIR filters with a bandwidth of 5 Hz. ABRs were calculated as previously described (see Fig. 3). For each subject, the four sessions were concatenated together prior to response calculation. For each stimulus frequency, the impulse train corresponding to the onset of each toneburst of that frequency was rectified and downsampled to match the EEG sampling rate. This was accomplished by taking the index of each impulse, multiplying it by the EEG sampling rate, dividing it by the stimulus sampling rate, and rounding to the nearest integer. The downsampled impulse train was then generated using these indices. All impulses were set to a magnitude of 1 such that rarefaction and condensation responses would average together to cancel stimulus artifact and so the responses had units of volts. These impulse trains (x) were then cross correlated with the EEG from that trial (y) and divided by the number of stimuli (n), yielding the ABR waveform (w), as shown in Eq. 1 (where \(\mathcal\) and \(\mathcal^\) correspond to the Fourier transform and inverse Fourier transform, respectively, and * corresponds to the complex conjugate), which is mathematically equivalent to averaging but more efficient to compute. For each trial, the impulse trains were zero padded and the EEG was padded with the surrounding waveform prior to moving to response calculation to prevent circular artifacts inherent to working in the frequency domain. For each subject, all trials for a given condition were averaged together using a Bayesian weighting technique, where the weights for a given trial were calculated as the inverse of the variance of the raw EEG for that trial and normalized such that the weights across trials summed to one. This method increases SNR by reducing the contribution of noisy trials to the average response. The responses for serially presented stimuli are calculated in the same way, except there is only one impulse train and one response to be determined.
$$\beginw=\frac}^\left\}^\mathcal\left\\right\}\end$$
(1)
Both authors picked the wave V peaks together for the grand average un-subtracted responses for later analysis, and TJS picked the peaks of the un-subtracted responses for all subjects. Peak picking was not fully blinded but was done without regard for stimulus condition. The peak-picking interface displayed the unlabeled waveforms across all HPN cutoffs and test frequencies for one subject at a time. While some aspects of the waveforms could provide information regarding the condition, we felt this was acceptable given the improvement in accuracy gained by the ability to use information of surrounding waveforms during picking. In plots and analyses comparing serial and parallel responses, the parallel response peaks were picked from only the ear from which the serial response was collected. When examining only the parallel condition, responses were averaged across ears prior to peak picking. Individual subjects did not always produce a response for each condition (i.e., at each HPN cutoff for all frequencies and rates). In these cases, the subject was excluded from latency calculations for that condition. In the un-subtracted responses, the latency of the peaks can be used to estimate the place specificity of the response since more basal regions of the cochlea produce responses with shorter latencies. In the derived responses, the magnitude of the response in different bands is used to measure place specificity.
Due to the low SNR of the derived responses, we computed the noise-adjusted standard deviation of the response within the expected response window, \(_\), to estimate the magnitude of the response. The latency at which a response was expected was determined by averaging the latencies of the two responses used to generate the derived waveform. We used the latencies from the grand average waveforms to determine the center of the analysis window, because subjects did not always have a response at each condition. The variance of the waveform within a 12 ms time window centered at this latency was calculated which represents the variance of the response plus the noise, \(_^\). Since the response and noise can be treated as independent random processes, the variance of the response (\(_^\)) can be estimated by subtracting the variance of the noise (\(_^\)). We estimated the variance of the noise by taking the variance of 40 non-overlapping 12 ms time windows taken from the prestimulus region of the waveform and averaging these variances. This estimate of the noise variance was then subtracted from \(_^\), yielding the estimated response variance \(_^\). This baseline correction was done separately for each subject and condition. We then took the square root of \(_^\) to determine the standard deviation which is more intuitive and has units matching the response waveforms (Eq. 2).
$$\begin_=\sqrt_^-_^}\end$$
(2)
When calculating the response variance to compare the serial and parallel conditions, parallel responses were only taken only from the ear matching that of the serial condition (i.e., responses from both ears were not averaged together), to avoid unfair comparisons due to differences in SNR. The serial and parallel response variances for each stimulus rate and test frequency were then plotted against the derived band center frequency to visualize the excitation pattern.
Statistical AnalysisAll statistical analyses were performed in R v4.3.2 [21]. Linear mixed effects models were fit using the lmer function in the lme4 package [22] from which ANOVAs were performed. All models included the subject identifier as a random effect and stimulus frequency, stimulus rate, HPN cutoff (or derived band), and their interactions as fixed effects. HPN cutoff or derived band was always represented as the difference (in octaves) between the HPN cutoff or derived band center frequency from the test frequency. Separate models were fit for the conditions where data existed to compare serial and parallel responses and to compare the parallel responses to each other (i.e., the 500 and 2000 Hz conditions). Models comparing serial to parallel responses also included paradigm and its interactions as a fixed effect. All effects were coded as factors in R. The observed variable for the un-subtracted responses was response latency, while the observed variable for the derived responses was response size (\(_\) from Eq. 2). Serial and parallel response latencies and sizes were compared with post hoc tests using the emmeans package [23], with adjustments for multiple comparisons using the multivariate t method.
Comments (0)