
Remember me

Philosophers have started to think about challenges and obstacles to implementing revised concepts and content (Nimtz 2024; Pinder 2017; Sterken 2020). However, there is a growing recognition that the implementation challenge should be tackled empirically (Andow 2020; Koslow 2022; Landes 2025; Pinder 2017; Thomasson 2021; Wakil 2023), but so far, the field has been slow to develop and deploy the necessary methods. Moreover, those who have used empirical data to study conceptual implementation have not directly tested the way specific theories play out in the process of propagating concepts, meanings, or words (Fischer 2020; Koslow 2022; Landes in press; Machery 2021).
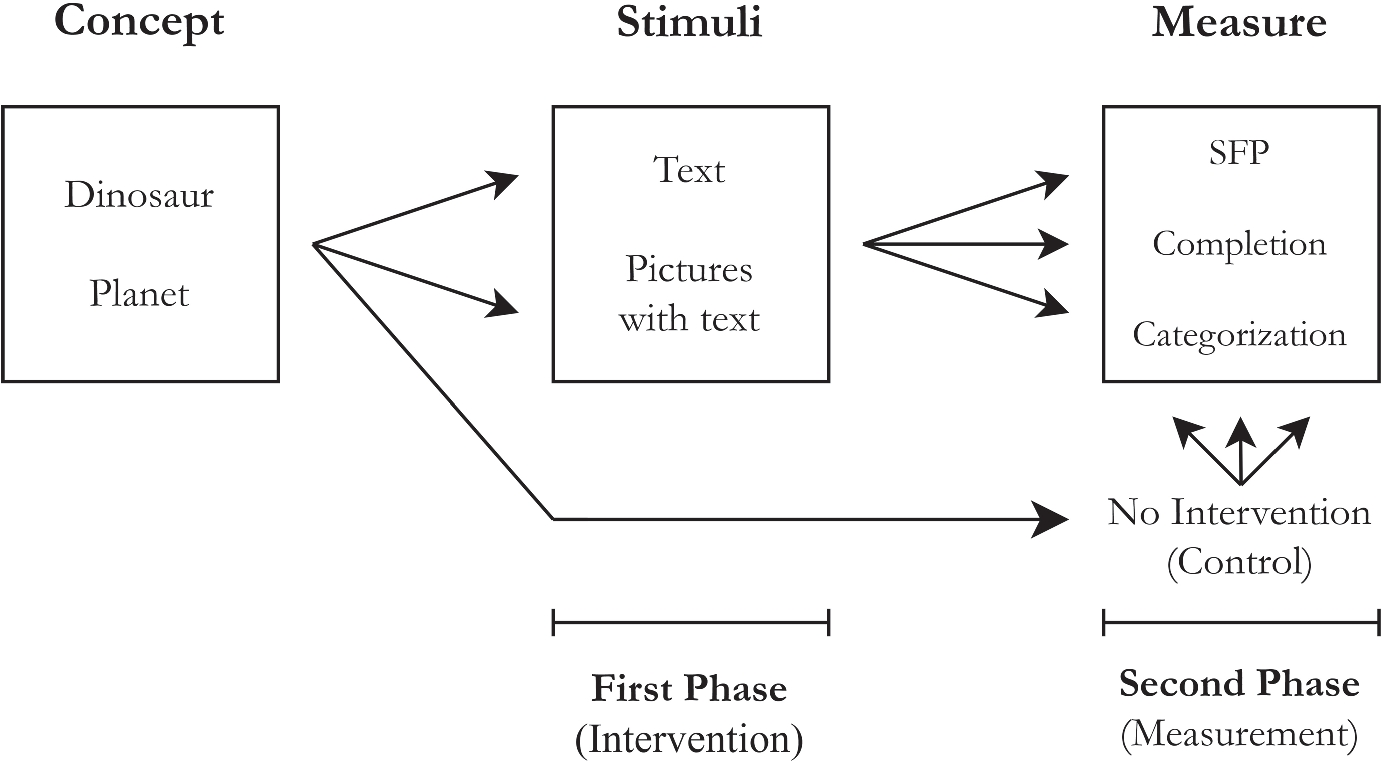
To address the current lack of suitable methods for measuring conceptual revision in adult populations, we argued for the use of masked time-lagged designs to directly research the implementation of conceptual change. By testing participants’ understanding at two different time points—without revealing that the second stage is connected to the first one—the method increases ecological validity and control over survey pragmatics, making it well-suited for studies on revision conducted on survey platforms. Our findings indicate that the masked time-lagged design offers a credible framework for conceptual engineers seeking to evaluate whether changes to established concepts can be effectively implemented.
Because masked time-lagged designs allow conceptual engineers to directly test questions related to propagation and implementation, the above findings about dinosaur and planet offer direct, albeit initial, insights into the factors that affect intentional conceptual revision. In Section 4.1, we address several limitations in our methodology before discussing in Section 4.2 how our findings offer first answers to the global and local implementation questions. In Section 4.3, we address the objection that our study measures changes in beliefs as opposed to changes in concepts. In the final section, Section 4.4, we expand the discussion to other conceptual engineering frameworks, arguing that masked time-lagged designs have utility beyond content internalist conceptual engineering frameworks.
4.1 Limitations of Main StudyBefore discussing specific inferences that can be drawn about conceptual revision, it is worth acknowledging a few limitations of the Main Study that prevent broader conclusions. Acknowledging these will help map the limits of what inferences can be drawn while also highlighting where future research would be most fruitful.
The first set of limitations is related to the project’s scope. Most straightforwardly, only two concepts were investigated. Dinosaur and Planet were the only concepts the authors collectively agreed met the ethical and pragmatic desiderata laid out in Section 2.1 and whose change was structured in a way that allowed for measurement using the three measures. Importantly, both planet and dinosaur are natural kind conceptsFootnote 12 as opposed to artificial kind concepts like table (see Gelman 2013; Rose and Nichols 2019), abstract concepts like truth, and social kind concepts like janitor—not to mention variations of each such as dual character concepts like artist (Knobe et al. 2013; Reuter 2019) and evaluative concepts like vandal (Eklund 2011; Willemsen and Reuter 2021). Another limitation of scope is the timeline of measurement. True revisionary uptake would last on the scale of years, not just hours and days, and it is an open question how much uptake of the sort measured above drops off over time. We found no evidence of an effect of time in the dataset, but future exploratory work should explore variations in duration to better understand the effect of time on conceptual uptake based on direct interventions.
The second set of limitations is related to the use of a two session between-subject design. This was chosen as the most likely method to result in successful masking. As discussed in Section 1.2, masking allows for valid comparisons between participants who had seen the intervention and had not, as we wanted to compare control data to genuine ecologically valid responses as opposed to responses driven by experimenter demand. Future research would greatly further the methodology of measuring conceptual change by exploring the possibility of masking two or three session within-subject designs or multi-session measurements extending over a greater timescale.
Third, the measures used in the Main Study that were drawn from the literature provide a limited view into what changed in the minds of participants. While coding the three measures allow for clean binary signals about the presence of the content of interest, each measure only produced between one and four data points about each participant’s conceptual content. This reveals only a small subset of a participant’s overall conceptual content, to say nothing of the content of their larger conceptual schema. The SFP and Completion task additionally under-count the conceptual content of interest. For example, “extinct” will not be someone’s only salient property of dinosaur, and it will not always be among a participant’s responses to free-response questions measuring salient properties. Therefore while the SFP and Completion tasks are not the best measure for approximating the prevalence of specific content in a population, they are still useful to test how content changes in response to interventions. In future work, alternative question types such as ranking questions or think-aloud protocols may yield richer and more accurate measurement of conceptual content from participants.
4.2 Advancing Global and Local Implementation QuestionsAs argued in Section 1, conceptual engineers have not made a clear distinction between factors that exert influence on implementation at a global level (i.e., all concepts) and those that impact implementation at the local level (i.e., specific concepts), and without direct empirical data concerning the implementation of specific concepts, it will be difficult to disentangle what sort of factors affect the propagation of all concepts versus what factors are limited to specific concepts. Given the study’s limitations, what tentative conclusions can therefore be drawn about global and local implementation questions?
Starting with global implementation questions, if both concepts behaved like dinosaur did, our results would have suggested that participants generally exhibit a high degree of resistance to conceptual revision. In such a scenario, we could have inferred that the process of implementing conceptually revised content is significantly more challenging than initially expected. This would be consistent with a particularly pessimistic reading of Machery’s attractor view (Kõiv 2024; Machery 2021)—in which psychological factors naturally attract us to certain conceptual content—where attractors are the norm, not the exception. In contrast, if dinosaur had been readily revised, it would have suggested even relatively surprising changes could be easily propagated in adults once the effort is put in to propagate the changes.
Our findings confirm the theorizing by others (Fischer 2020; Koslow 2022; Machery 2021) that the picture is significantly more complex. Across all four interventions, we observed that individuals can be effectively instructed to categorize objects based on new classification schemes with relatively short interventions. Spending a few minutes informing individuals why Pluto is not a planet and why birds are dinosaurs brought about substantial changes in participants’ classification patterns. Across all interventions, when presented with an image of Pluto and asked about its planetary status or shown a picture of a seagull and queried about its classification as a dinosaur, participants successfully categorized the objects according to the taught schema. Consequently, it appears that the process of revising individuals’ mental representations in order to elicit accurate responses to questions regarding the superordinate categorization of Pluto and birds is relatively straightforward.
If the objective of a conceptual engineering project is to induce individuals to modify their explicit classification scheme, these findings are encouraging. To some engineers, this might be enough. However, the aspirations of many engineers extend beyond merely altering individuals’ classifications (Isaac et al. 2022). Their ultimate goal lies in transforming people’s reasoning patterns, enabling them to draw inferences based on their newfound knowledge and perceive the world through different perspectives. Accomplishing this likely necessitates the modification of individuals’ associations and implicit reasoning processes.
Changing implicit associations and default information retrieval looks to be much more difficult. While the Categorization task uniformly resulted in large differences in expert-inconsistent responses between the control group and test groups, the Completion task and the Semantic Feature Production task results were mixed. In the Completion task and the Semantic Feature Production task, sizable differences were seen between the control and test groups for planet—a difference of around 20% expert-inconsistent responses among the conditions’ participants—but no such changes were observed for dinosaur. Consequently, it appears that modifying individuals’ explicit classification schema is significantly more feasible than altering salient features and what information is retrieved by default.
Turning now to local questions—that is, questions about what factors influence the revision of specific concepts—the contrast of different conditions and concepts offers two insights into why we were successful in revising planet. First, the control data in the masked time-lagged study and responses in the Follow-up Study both indicate the revision of planet is better known than the revision of dinosaur among adults. Perhaps the increased awareness of planet played an important role in its success, suggesting conceptual revision is something that should be built up to instead of something that can be done in a single intervention (see Carey 2011). The difference in effectiveness of the two planet stimuli offers another clue.Footnote 13 Adding pictures and detail to our stimuli did not by itself have an effect on conceptual revision, as evidenced by lack of revision of dinosaur among participants who saw the longer intervention containing images. However, length and different format appear to have played some role in uptake of the revised planet, suggesting that multi-modal formats may be a useful tool for propagating revisions like it.
To summarize, results support a few tentative conclusions about propagation that may serve as the basis for future work:
Global Level:
1.Short explanatory stimuli are capable of revising some natural kind concepts.
2.For natural kind concepts, changing classification patterns appears to be relatively straightforward.
3.For natural kind concepts, it is more difficult to modify associations and information retrieved by default than classification patterns.
4.Changes involving splitting and/or shrinking concepts may prove easier than changes involving combining and/or expanding concepts (see Fischer 2020).
Local Level:
1.planet’s ease of revision may have depended on previous exposure.
2.Visual aids may have helped revise planet.
Up until this point, our discussions and interpretations have assumed that our measures capture conceptual revision in planet. In the next section, we respond to the objection that in fact the measures capture something non-conceptual.
4.3 Objection: This Is Only Belief RevisionHow confident can we be that we observed a conceptual change instead of a belief-based change? The question is complicated by two factors. First, there is substantial disagreement among content internalists in philosophy and cognitive science about how to demarcate conceptual content and how content is structured (see Bloch-Mullins 2018; Quilty-Dunn 2021; Vicente and Martínez Manrique 2016; Yee and Thompson-Schill 2016), which leads to different views about where the line between beliefs and concepts lie. Answering this first complication is beyond the scope of this paper. Given the complexity of the literature on conceptual structure, the measures we used above will not satisfy everyone, nor would it be feasible to test every account in the literature at once. Nonetheless, one of the primary purposes of this paper is to provide methodological scaffolding for future projects. Anyone who believes a different measure would better capture what they think conceptual content is can easily swap in their own measures.
Second, on many content internalist frameworks, the distinction between beliefs and concepts is very subtle. This second complication is something the above experiment does accomplish to navigate, at least on one prominent account of content internalist conceptual engineering. The two invariantist conceptual engineers whose work we draw the Completion measure from, take concepts to be belief-like in that they are stable bodies of information (Fischer 2020; Machery 2017). On their account, what makes concepts unique is that they are retrieved quickly, automatically, and independent of context, which means they affect inferences, categorizations, and other cognitive functions (Machery 2017, 210-211). For example, someone may correctly believe that—due to the geography of French Guyana—France’s longest border is with Brazil, but not have this information elicited quickly, automatically, and independently of context when they read the word “France”. Instead, the information retrieved by default may involve Paris, the French flag, France’s European borders, and/or facts about France’s economy. This retrieved information, as it changes from person to person, is someone’s concept of France on such an account, while the belief about France’s border with Brazil is not. As discussed above, the masked time-lagged design was designed to test responses to stimuli without the contextual and pragmatic salience of the intervention. Thus, the design approximates default, low-context responses—that is, content as opposed to mere belief according to Machery (2017) and Fischer (2020)—as much as is methodologically possible (for general doubts about the possibility of this, however, see Casasanto and Lupyan 2015).
Setting aside specific frameworks of conceptual content, consider some general reasons to think that the above results can be viewed as capturing conceptual revision in action. This needs to be discussed in two parts because in the above experiment, the three measures followed two patterns. The Categorization task—a multiple choice question about scientific kinds—changed dramatically, regardless of stimuli or concept. The other two tasks, Completion and SFP, both of which were open-ended free responses, only significantly changed in response to one of the four stimuli. This suggests that the Categorization task is picking up on different, more plastic, phenomena than the SFP and Completion tasks. Categorization is taken to be one of the key functions of concepts (Bloch-Mullins 2018; Machery 2009), and so we take the default reading of these findings to be related to concepts. However, one significant possibility, not ruled out here, is that the more plastic phenomena are beliefs as opposed to anything properly considered concepts. On such a reading of the results, participants are changing how they categorize Pluto and seagulls, not because of any change in conceptual content, but because of belief-level phenomena, such as the belief in the facts Pluto is not a planet and birds are dinosaurs. That is, the Categorization task, despite the intention behind its inclusion in this test, is acting as more of a test of scientific knowledge rather than how participants automatically classify objects.
However, beliefs are not the only thing that would explain the increased plasticity of the Categorization task over the other two tasks. Another possibility is that the Categorization measure is more sensitive to particular kinds of conceptual change than the SFP and Completion measure, namely the development of polysemy.Footnote 14 For example, there are multiple terms that are polysemous in that they have a loose folk meaning and a more precise scientific meaning. In the everyday sense of “fruit”, tomatoes are not fruit, but in the technical sense of “fruit” tomatoes are fruit (Engelhardt 2019; Landes 2021; Machery and Seppälä 2011). Being able to understand the senses in which tomatoes are and are not fruits requires two distinct concepts, specifically fruit as a culinary/social kind and fruit as a botanical kind. A possible outcome of attempting to revise planet and dinosaur is that, like fruit, people end up with two concepts—folk and scientific counterparts to each other—which the Categorization task is for some reason more sensitive to in a way the SFP or Completion tasks are not.
That said, even if we grant that the Categorization task is merely picking up on changes of belief, this skepticism does not extend to the other two measures. For one, the SFP task does not seem to be picking up on beliefs because the information it collects is not obviously propositional and so not obviously belief-driven in the way the Categorization task may be. The SFP task asks participants to list what features come to mind related to some object. Therefore, the SFP task appears to be best interpreted as measuring salient properties of the concept as opposed to mere beliefs about the kinds (Machery 2009; McRae et al. 2005) and so is perhaps best understood as measuring stereotypical or prototypical information. Moreover, because the results of the Completion Task closely follow the results of the SFP task in all interventions, the responses in the Completion and SFP tasks appear to have a common etiology.
4.4 Expanding the Method to Other Conceptual Engineering FrameworksThe experiment and resulting data has been discussed through the lens of content internalist conceptual engineering, which understands the target of conceptual engineering to be concepts and understands concepts to be token psychological entities. While this is currently a popular conceptual engineering framework, it is by no means the only one on the market. Other frameworks include those that propose that the goal of conceptual engineering is semantic meaning (Cappelen 2018; Sterken 2020), speaker meaning (Pinder 2020, 2021), or conceptual content that is grounded in facts external to individuals (Haslanger 2020; Sawyer 2020; Scharp 2013). In this section, we discuss the significance of the masked time-lagged method to other frameworks. We specifically focus on two prominent families of frameworks that focus on language instead of concepts, namely speaker meaning accounts and semantic externalist accounts.
The methods described above can easily be expanded to speaker meaning accounts of conceptual engineering. Speaker meaning accounts of conceptual engineering take the goal of conceptual engineering to be to change what people take themselves to mean by the words that they utter (Pinder 2020, 2021). Speaker meaning conceptual engineers do not aim to change what a word means in some broad, interpersonal sense. Instead they target the intentions and beliefs speakers have related to using a specific term (although on some frameworks, linguistic intentions, linguistic beliefs, and meaning go together). Thus, similar to content internalist frameworks, speaker meaning conceptual engineering places the target of conceptual engineering in token psychological states. The best way to test what speakers intend to mean by a term is to have them produce speech acts using the term and coding how the term is used. For that reason, the Completion task may be a suitable measure, although multi-sentence productions would provide richer sources of data about speaker intentions.
When it comes to applying the findings of our studies to semantic externalist frameworks of conceptual engineering, the extension of this study is not as straightforward because semantic externalists do not place the focus of their theories on token psychological states. Nonetheless, when we dig into the role token psychological states generally play in semantic externalist accounts of meaning, we can see that not only can masked time-lagged designs answer questions about how to spread true beliefs about meaning or reference changes that has already occurred, it can also answer questions about how best to use our limited ability to change externalist meaning or reference.
Externalists will not want to say that our experiment revised the concept Planet or meaning of “planet”. They will instead contend either that a) “planet” always excluded Pluto (e.g., Ball 2020; Kripke 1980, b) the concept or meaning was revised in 2006 by the International Astronomical Union, or c) revision of “planet” or Planet occurred at some later date when, for example, the new linguistic norm became the dominant one among English speakers (Evans 1973).Footnote 15 Even if semantic externalists contend our experimental data does not reveal anything about how to change meaning, the experiment does shed light on how conceptual engineers can help individuals become aware of changes in meaning. While on many of these frameworks, the meaning of people’s utterances containing“planet” has changed since 2006, these sorts of changes can happen without people’s awareness (see Pollock 2021; Wikforss 2015). Thus, externalists can still view the experiment as testing phenomena related to propagation. While the experiment did not change meaning, it propagated true beliefs about the meaning of “planet” in light of changes that have occurred.
The masked time-lagged design can do more than show how to spread true semantic beliefs related to revisions, however. Semantic externalists can use the masked time-lagged design proposed here to determine the most effective ways to change meaning—even if meaning is grounded externally to individual speakers. To see this, we need to focus on what externalists take ground semantic facts. For semantic externalists, the meaning of a word-type or utterance-type (that is, what a word means, in general) is determined by some combination of linguistic facts and non-linguistic facts. While they disagree about which linguistic and non-linguistic facts matter, many, if not most non-linguistic facts, such as the joints of natural kinds, are outside of conceptual engineer controls (Cappelen 2018). This limits the scope of what sort of changes are possible. Nonetheless, many meaning-determining linguistic facts are within the scope of empirical methods (Koslow 2022; Sterken 2020; Thomasson 2021), and a subset of those meaning-determining facts are things conceptual engineers have (limited) influence over. This is because many linguistic facts are grounded in, among other things, intentions and beliefs of individual speakers—that is, token psychological states (see Nimtz 2024).
To illustrate how global and local questions about intentional semantic externalist meaning change can be tested, consider a version of an Evans-style metasemantics, where the reference of a word-token is determined by the dominant causal source of all the uses of that word-token (Evans 1973; Leckie and Williams 2019). On this view, my use of “cat” refers to cats because most of the people around me use “cat” in a way that traces back to cats. What things there are in the world to be a dominant causal source is by and large outside of conceptual engineers’ control. Nonetheless, this Evan-style view locates part of the ground of reference in the collective uses of a community of speakers. The collective use of a community of speakers is, at rock bottom, a large number of token beliefs and practices about language. Therefore, changing meaning by changing psychological states is possible if enough psychological states change to disrupt the current dominant source (see Sterken 2020). How to best use resources to disrupt the dominant source is something experimental methods can study. In fact, this will look similar to the speaker meaning account discussed above, as it will involve studying how people shift the way they speak in light of an intervention.Footnote 16
The Evans-style view is merely illustrative of the larger constellation of semantic externalist theories. Semantic externalists generally take some sort of linguistic norm or practice to play a role in determining the meaning of word-types, such as the collective use of a causal historical chain (Kripke 1980) or linguistic conventions (Lewis 1969). Linguistic norms and practices are partially or wholly composed of linguistic beliefs and intentions, although the way linguistic beliefs and intentions combine to form norms may be extremely complicated (Lewis 1969; Nimtz 2024). This means that semantic externalists can study how to change meaning by studying how to bring about collective shifts in linguistic beliefs and intentions. Here we find ourselves in the realm of token psychological entities, and so semantic externalists can test what factors influence meaning or reference change using variations of the above empirical masked time-lagged design. Granted, no amount of experiments will make externalists semantically omnipotent—they will still be limited in what they can change by linguistic and non-linguistic facts outside of their control. This is not a problem unique to externalism, however. As discussed above, internalist conceptual engineers will also be limited by features of our cognition that will prevent certain proposed changes from taking hold. Nonetheless, the more we learn through experiments about how the grounds of conceptual content or semantic facts change, the better conceptual engineers will be at revising or replacing conceptual content or semantic facts.
Comments (0)