
Remember me


The current study was based on data acquired from the UKB resource, which is a large population-based cohort with extensive health-related data on more than 500,000 individuals, aged 40 to 69 years, with an almost equal distribution between men and women (Sudlow et al. 2015).
All the participants provided written informed consent for their data to be used in future research with the possibility to withdraw at any time and the UK Biobank project has been approved by the UK Biobank Research Ethics Committee (REC), (REC reference 11/NW/0382). This study was conducted using the UK Biobank Resource under application number 30172 and for our use of UK Biobank data, an approval was obtained by the Regional Ethics Committee of Uppsala, Sweden (2017/198).
Genotype DataIncluded Studies for Gene SelectionA summary of the steps to create the genotype data is shown in Flowchart 1. We focused on genes with potential functional association with TN. Based on the results of four previous proteomic studies conducted by our research group (Ericson et al. 2019, Abu Hamdeh et al. 2020, Svedung Wettervik et al. 2022, Lafta et al. 2023), we aimed to validate these findings on the genetic level to enhance our comprehension of the role of genetics in TN. Of these four studies, three utilized Olink Proximity Extension Assay technology, while the fourth employed in-depth mass spectrometry. We compiled the key findings from each study, specifically the proteins and their corresponding genes, resulting in a total of 17 genes.
Flowchart. 1
Flowchart showing the steps for the generation of the genotype data. Abbreviations: SNP, single nucleotide polymorphism; LD, linkage disequilibrium; HWE, Hardy–Weinberg Equilibrium; MAF, minor allele frequency
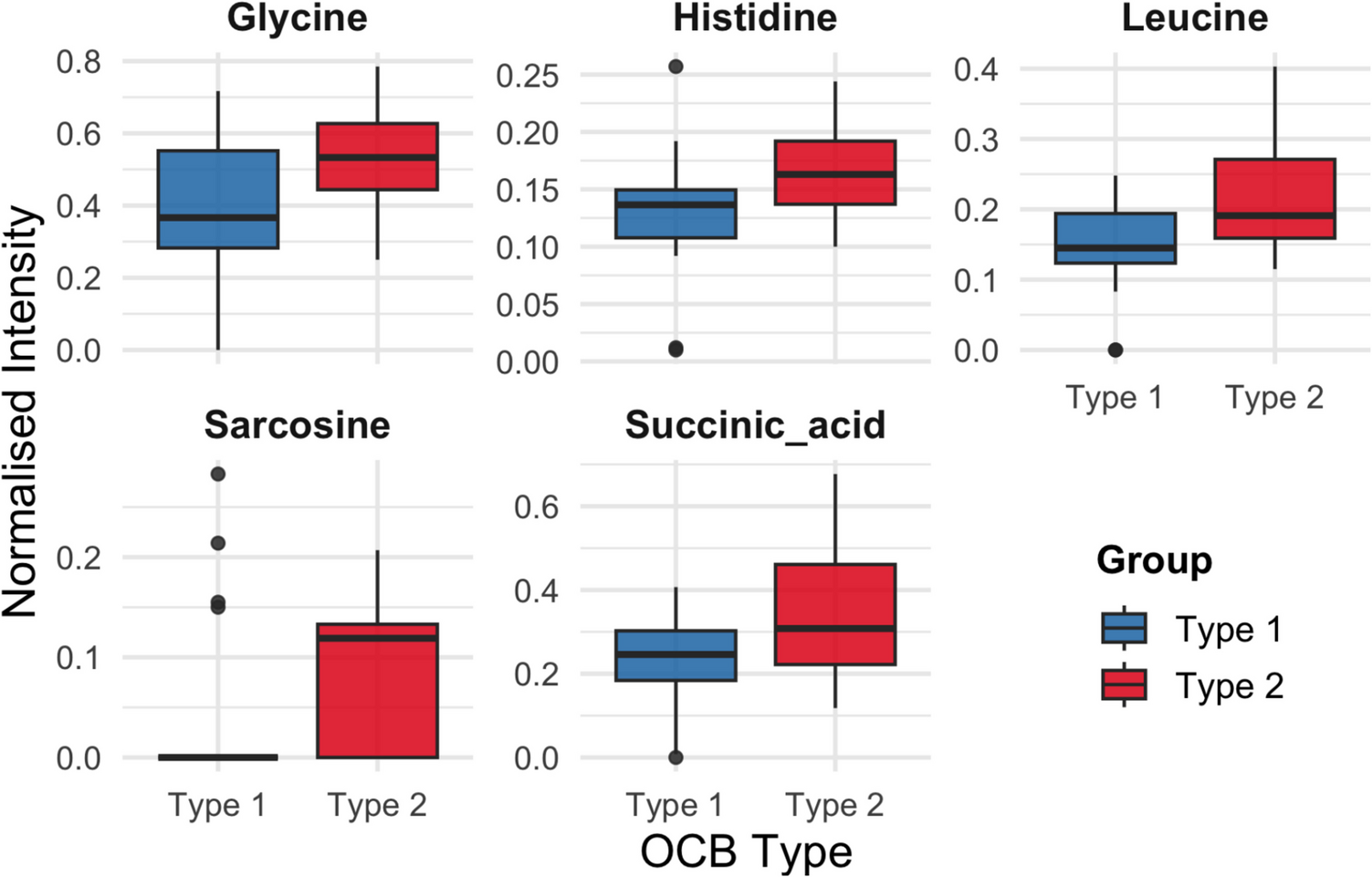
In the first study by Ericson et al. (Ericson et al. 2019), a panel of 92 protein biomarkers related to inflammation in lumbar cerebrospinal fluid (CSF) from patients with TN (n = 27) was compared to individuals without TN. Two proteins, TRAIL and TNF-β, were identified as being of specific interest for TN. In the second study by Abu Hamdeh et al. (Abu Hamdeh et al. 2020), lumbar CSF from TN patients (n = 17) and from controls was analyzed using in-depth mass spectrometry. The study identified apolipoproteins (APOC-2, APOA4, APOM, APOA1, and PON1) and proteins involved in the complement system (C5, C8B, and C8G) as elevated and significantly over-represented. In the third study by Wetterwik et al. (Svedung Wettervik et al. 2022), differences in protein expression of 91 CSF proteins of TN patients (n = 16) in relation to controls were explored. The TN patients exhibited higher concentrations of Clec11a, LGMN, MFG-E8, and ANGPTL-4 in CSF than the controls. And lastly in the fourth study by Lafta et al. (Lafta et al. 2023), protein expression levels in both serum (n = 33) and CSF (n = 27) were explored in TN patients compared to multiple sclerosis (MS) patients and controls. The main findings included three proteins related to neuroinflammation (SFRP1), chronic stress (FKBP5), and neurodegeneration (TBCB) in TN patients.
Filtering Steps for SNP SelectionThe UCSC Genome Browser database was used to identify all the SNPs associated with each of these selected 17 genes. The UCSC Genome Browser, hosted by the University of California, Santa Cruz (UCSC), serves as a comprehensive open-access knowledge platform, accessible both online and for download (Rosenbloom et al. 2012). The associated SNPs were collected from the latest release of dbSNP153 obtained from the UCSC Genome Browser. Gene coordinates were obtained for each gene using the longest corresponding transcript from NCBI RefSeq track. Genome assembly GRCh37/hg19 was used in all steps.
We applied a tool, bedToBigBed from UCSC, to extract SNPs based on specified genetic coordinates solely within the complete length of the gene, without any base pairs located outside the gene's boundaries. The obtained list of SNPs was then further filtered to include only SNPs with a minor allele frequency (MAF) of 0.1 or higher in the 1000 Genomes Project. We chose this high allele frequency threshold based on evidence that loci with a low MAF (< 10%) have significantly lower power to detect weak genotypic risk ratios than loci with a high MAF (> 40%) (Ardlie et al. 2002). Furthermore, previous studies have demonstrated that rare genotypes are more likely to result in spurious findings (Lam et al. 2007).
Lastly, to identify independent variants, specifically SNPs that are not in linkage disequilibrium (LD) with each other, we analyzed one gene at a time and examined the LD within each SNP pair using r2 as a measure of LD (SNPs with r2 < 0.8 were selected). LD is the statistical correlation between alleles at different loci, providing valuable information about the evolutionary forces affecting a population as well as the genetic basis of complex traits and diseases (Slatkin 2008). We used an R package, LdlinkR (Myers et al. 2020), to prune the list of SNPs by LD on a chromosomal basis with r2 set to 0.8, MAF set to 0.1, and the default CEU population. These filtering steps yielded a total of 184 independent SNPs for our 17 genes. Finally, we extracted the genotype data for each SNP from the UKB, using two different filters to exclude SNPs with genotyping rate < 0.988 and/or missing rate > 10%. This resulted in a final number of 175 SNPs that were used in the analyses.
Phenotype DataA summary of the steps to create the phenotype data is shown in Flowchart 2. In the UKB, phenotypic data was available for 502,696 participants. We excluded participants who had withdrawn their consent, were genetically related (UKB FID: 22021), or were non-European (UKB FID: 21000), which yielded a final number of 292,161 participants. The cases for TN were identified using the International Classification of Diseases (ICD-10) code G50.0 for TN. Participants were determined as cases if they either had a primary or secondary diagnosis of TN from linked hospital admission records, which yielded a total of 555 cases.
Flowchart. 2
Flowchart showing the selection of study samples for trigeminal neuralgia (TN) cases and controls
The controls were derived from participants who did not meet the above-mentioned criteria for the definition of cases. We utilized a case–control matching procedure in SPSS, randomly pairing cases with controls based on criteria known to affect the incidence and prevalence of TN. This method also facilitated the examination of the effects of SNPs on TN, ensuring that the comparison between groups was robust and accounted for potential confounding factors that could influence our study's findings. We selected controls based on age (UKB field ID (FID): 21022), sex (UKB FID: 31), BMI (UKB FID: 21001), antiepileptic medication (UKB FID: 20003), alcohol drinker status (UKB FID: 20117), smoking status (UKB FID: 20116), and general health status, including happiness (UKB FID: 4526), family relationship satisfaction (UKB FID: 4559), friendships satisfaction (UKB FID: 4570), mental satisfaction (UKB FID: 4548), financial situation, and satisfaction (UKB FID: 4581). With the tolerance level of zero for all variables, except 1 for age and 0.5 for BMI, our case–control matching yielded a total number of 6,245 controls.
For other potential confounding reasons, we collected data on the prevalence of other common co-morbid conditions and reported the occurrence of each condition among both cases and controls (Table 1). These conditions included MS (ICD: G35), hydrocephalus (ICD: G91.0, G91.1, G91.3, G91.8, G91.9), epilepsy (ICD: G40-G41), sleep disorders (ICD: F51.0, F51.8, F51.9, G47.1, G47.8, G47.9, Z91.3), mental health disorders (ICD: F10-F99), dementia (ICD: F00-F02, G30-G32), brain tumors (ICD: C71), and cerebrovascular diseases (ICD: G46, I61, I63-I64, I67). However, for sample size reasons, and despite the distribution not being perfectly balanced between cases and controls, we did not exclude these conditions since exclusion would significantly reduce the number of participants.
Table 1 Demographic characteristics of the final sample populations of trigeminal neuralgia (TN) cases and controlsStatistical AnalysesEach SNP was coded as follows: (0) for homozygous for the major allele, (1) for heterozygous genotype, and (2) for homozygous for the minor allele. Using a case–control design, binary logistic regression models, adjusted for age, sex and first ten genetic principal components, were fit to compare the genotypes of TN cases with controls. Furthermore, sensitivity analyses were conducted for significant associations in the main analyses after excluding cases with TN as secondary diagnosis (n = 319). Thus, n = 236 cases were included in the sensitivity analyses. All analyses were conducted using Statistical Software for Social Sciences (SPSS) and R. To account for multiple comparisons, Bonferroni correction was applied and statistical significance level was set at P ≤ 0.00029 (0.05/175 based on the total number of SNPs included in the analysis).
Genotype-Tissue Expression (GTEx) portalTo investigate the association between SNPs and gene expression, the public Expression Quantitative Trait Locus (eQTL) database, the Genotype-Tissue Expression (GTEx) portal, was searched. The GTEx Project was designed to enable studies of the relationships among genetic variation, gene expression, and other molecular phenotypes across multiple human tissues (GTex Consortium 2013). The database contains data on eQTLs derived from analyses performed in whole blood. Details on the eQTL analyses are explained both in other sources (GTex Consortium 2013) and on the GTEx website.
Comments (0)