
Remember me
Traffic forecasting is a fundamental component of intelligent transportation systems (ITS). The primary goal of traffic forecasting is to identify key factors influencing traffic variation based on historical observations, develop prediction models, and forecast future traffic conditions (Yu, 2021; Rong et al., 2022). Traffic forecasting is typically categorized into short-term and long-term predictions, depending on the forecast horizon. In this study, the focus is on short-term predictions, which generally aim to forecast traffic conditions within the next hour. It is particularly significant in the real-world context of ITS for several reasons (Ji et al., 2023; Li et al., 2025). First, accurate short-term forecasts directly benefit travelers by providing more precise travel time estimates, which help individuals make informed decisions about their departure times and route choices. This can lead to more efficient traffic distribution and reduced overall travel time (Bie et al., 2024; Luo et al., 2024). Furthermore, for transportation operators, effective short-term forecasting enables the implementation of real time management strategies, such as dynamic route guidance. This helps mitigate congestion before it reaches critical levels and reduces the risk of accidents (Sun et al., 2018a,b). However, short-term traffic forecasting also faces specific challenges, particularly due to the stochastic nature of traffic flow and the influence of external factors such as weather, accidents, and special events.
In pursuit of more accurate traffic forecasting accuracy, many methods have been explored. These methods typically take historical traffic data as input or combine it with other actual data sources. Through a variety of means, they mine the characteristics within the traffic flow data to achieve predictions of traffic flow features, such as traffic flow speed or traffic volume. They are mainly divided into two categories: model methods based on linear statistical theory and nonlinear theory. Methods based on linear statistical theory, such as historical mean prediction, time series prediction (Ma et al., 2021; Han, 2024), Kalman filtering prediction (Okutani and Stephanedes, 1984; Zhang et al., 2023), are characterized by their simplicity, ease of implementation, and low computational cost for a single prediction. However, they usually fail to address the uncertainty and nonlinearity of traffic flow, thereby lacking the capability of effective prediction in complex environments. Nonlinear theoretical model-based methods mainly include wavelet analysis (Wang and Shi, 2013; Dong et al., 2021), chaos theory (Shi et al., 2020), neural network, and support vector regression (Omar et al., 2024). Among these, wavelet analysis models and chaos theory can extract nonlinear characteristics and achieve relatively high accuracy, but due to their high complexity, research on traffic forecasting based on these methods is relatively limited (Zhang et al., 2018). Neural network models and models based on support vector regression have rich parameters and strong fitting ability for complex nonlinear relationships, making them the mainstream prediction methods currently employed (Wang et al., 2023; Wang J. et al., 2024).
Early neural network models are essentially shallow neural networks (NN), which were unable to comprehensively extract the fundamental features from traffic data. Therefore, neural network models with multiple hidden layers (MHL), such as Multilayer Perceptron (MLP), have gradually been applied in traffic forecasting (Oliveira et al., 2021). With the increase in model complexity, the network’s ability to extract traffic features enhances, but at the same time, it requires a larger number of training samples and the prediction time per single training also increases. Due to computational limitations, early machine learning algorithms did not demonstrate significant advantages in traffic forecasting problems. In 2006, Hinton et al. introduced the first Deep Learning (DL) paper, highlighting two key insights: deep neural networks with MHL excel at feature learning, providing a more fundamental data representation, and “layer-wise pre-training” effectively mitigates the challenges of training deep networks. The publication of this article sparked the wave of research in DL (Nigam and Srivastava, 2023).
Recurrent Neural Networks (RNN) (Pascanu, 2013), along with variants like Long Short-Term Memory (LSTM) (Schmidhuber and Hochreiter, 1997) and Gated Recurrent Unit (GRU) (Yang et al., 2022), are effective at handling sequential data and conducting complex transformations. These capabilities enable them to capture temporal dependencies in traffic flow, making them ideal for time series forecasting (He et al., 2022). In addition, with the widespread use of surveillance equipment, convolutional neural network (CNN) models, which rely on image data, have been introduced into traffic forecasting (Parishwad et al., 2023). Based on the multilayer convolution structure inherent in CNN models, these models can effectively capture spatial correlation characteristics of traffic flow (Narmadha and Vijayakumar, 2023). On the other hand, graph neural networks (GNNs) models (Scarselli et al., 2008), which are based on graph-structured data, have also been applied to traffic forecasting. GNNs are good at modeling the relationships between different nodes in a traffic network, especially in capturing topological structures and interactions. They are suitable for scenarios where the spatial relationship between roads and intersections plays a vital role. Subsequently, Transformer-based models (Vaswani et al., 2017) have gradually shown great potential in traffic forecasting problems. Compared with other traffic forecasting methods, Transformer can simultaneously focus on different positions of the input sequence through its unique multi-head attention mechanism, thereby more comprehensively capturing long-distance dependencies and complex features in traffic data. In addition, the architecture design of Transformer allows it to perform parallel calculations, greatly improving the training efficiency. Compared with some methods based on CNNs/GNNs, it has obvious speed advantages when processing large-scale traffic data sets, and can adapt to dynamic changes in traffic conditions more quickly, providing a more efficient solution for real time traffic forecasting (Eleonora and Pinar, 2023; Chen et al., 2024; Zoican et al., 2024; Guo B. et al., 2024; Guo X. et al., 2024).
However, existing methods still have limitations. For example, traditional graph-based models may face challenges of high computational complexity due to complex graph convolution operations and strict dependence on road topology. Similarly, in the Transformer’s self-attention, while it typically uses all node information to compute attention weights, the traffic network, composed of roads and intersections, has complex spatial relationships that cannot be captured by a simple linear sequence. As a result, the current approach introduces unnecessary interactions and noise, limiting its ability to fully capture the network’s spatial characteristics. Taking into account the complexity of traffic flow and the limitations of existing methods, the historical traffic flow data sequence and road topology information of traffic nodes are used as the core input data source. A DL framework based on the Transformer encoding module is constructed to achieve accurate prediction of future traffic speed at traffic nodes. Specifically, spatial masks based on spatial topology and travel time are designed. In this way, spatial information is effectively introduced, significantly enhancing the model’s ability to capture spatial relationships in complex urban traffic scenarios and greatly improving traffic flow prediction accuracy. In addition, a streamlined and effective MLP is used to replace the original complex decoding structure of the Transformer. This reduces the computational complexity and the number of network layers while ensuring that the prediction accuracy is not compromised. The main contributions of this work include:
1. Using the road network topology to generate spatial masks, so that the model can take more into account the traffic nodes with spatial connections during feature interaction, which reduces the unnecessary interaction and noise.
2. Introducing a Transformer-based traffic forecasting model, which can effectively handle long-term dependencies in spatiotemporal traffic information and provide more interpretability.
3. Conducting multiple sets of comparative experiments and ablation studies using a large-scale real road network dataset to assess the model’s performance, accuracy, and its internal components.
The remainder of the paper is structured as follows. “Literature review” covers DL-based traffic forecasting methods. “Methodology” introduces the DL framework established in this study. “Experiments” validates the proposed approach with real world datasets. The research conclusions and prospects are presented in “Conclusions.”
2 Literature reviewAs a core part of ITS, traffic flow prediction aims to anticipate traffic conditions, such as traffic flow speed, traffic flow volume, enabling authorities to take preemptive measures and travelers to plan better. However, traffic flow is complex, affected by various factors. Traditional prediction methods struggle to capture its dynamic nature. With computing power growth, machine learning, especially DL, has emerged as a leading solution (Zhu et al., 2021; Mohammadian et al., 2023; Ding et al., 2024; Chen et al., 2024; Wang Q. et al., 2024). Different DL architectures offer unique strengths in handling traffic flow data. RNN and their variants, like LSTM, are designed to handle sequential data, making them suitable for capturing temporal patterns in traffic flow. CNN excel at extracting spatial features, which is vital for understanding the relationships between different traffic nodes (Li et al., 2024a). And Transformer, with its attention mechanism, can model full dependencies, better handling long-range correlations in traffic. Hence, the following sections will explore these three categories of DL-based traffic forecasting methods.
2.1 Traffic forecasting based on RNNRNN and their improved architectures are a highly utilized class of NN in the field of traffic forecasting. Tian and Pan (2015) developed a recursive LSTM model that incorporates three multiplication units in the memory block, allowing for dynamic selection of the optimal time lag from historical input, leading to better prediction accuracy. Zhao et al. (2017) constructed a two-dimensional LSTM network with multiple memory units to facilitate short-term traffic flow forecasting. They also compared the established model with other representative prediction models to verify its effectiveness. Yu et al. (2017) constructed a hybrid deep model based on LSTM for traffic forecasting under extreme conditions and realized the joint simulation of traffic flow states under normal conditions and accident modes. A bidirectional RNN module was used by Liu et al. (2017) to analyze historical traffic data at nodes, uncover periodic traffic flow patterns, and incorporate them into urban traffic forecasting. Fang et al. (2023) reconfigured the loss function in LSTM based on the negative guidance mixed correlation entropy criterion, aiming at the prediction error caused by non-Gaussian noise, and constructed a delta-free LSTM framework for short-term traffic flow prediction.
2.2 Traffic forecasting based on CNNCNNs have been utilized by some researchers for traffic forecasting tasks. They use multilayer convolutional structures and their combined networks to extract the spatiotemporal correlation features of traffic flows. Ma et al. (2022) built a feature selection algorithm based on the combined units of CNN and GRU, and combined the positive and reverse GRU networks to mine the long-distance dependencies in the input information to increase the accuracy of predictions. Wang and Susanto (2023) used CNN to represent and process features such as traffic flow change patterns in different time periods in a way similar to image features, so as to better understand and use the information in time series data to predict traffic flow. However, traditional CNN frameworks are better suited for processing data with uniform size and dimension, typically found in Euclidean structure data. In the context of traffic networks, the road connections between traffic nodes may not be uniformly distributed, and the feature matrix dimensions of nodes may also vary. Therefore, the spatial characteristics learned by CNN may not necessarily represent the optimal features of the traffic network structure. The introduction of graph convolutional networks (GCN) (Kipf and Welling, 2016) has brought breakthroughs in the application of CNN in non-Euclidean structured data (Gong et al., 2023; Guo B. et al., 2024; Guo X. et al., 2024). By using the topological structure information of the graph to adjust the convolution operation, CNN can better adapt to the irregular data distribution and complex node relationships in the traffic network, thereby significantly improving its performance in tasks such as traffic forecasting (Li et al., 2023).
2.3 Traffic forecasting based on transformerTransformer, as one of the variations of DL network architectures, was introduced by Vaswani et al. (2017). It models the full dependencies between inputs and outputs using attention mechanisms. Models and frameworks based on Transformer can better handle long-range dependencies in traffic flow data, exhibiting relatively higher flexibility. Based on the overall architecture of Transformer, Cai et al. (2020) identified the continuous and periodic patterns in traffic time series, modeled the spatial dependence of the road network, and finally verified the model’s impact through two real data sets. Yan et al. (2021) used the combined framework of the global encoder and the global–local decoder to realize the extraction and fusion of global and local traffic flow features and achieved high-precision prediction of urban traffic flow. Chen et al. (2022) constructed a dual-directional spatiotemporal adaptive transformation framework based on codec-decoder structure to address the uneven spatiotemporal distribution in traffic prediction, and verified its effectiveness on four datasets. Wang F. et al. (2024) proposed a comprehensive network based on Transformer and GCN to capture the complex spatiotemporal correlations in metropolitan area networks and achieve more accurate traffic forecasting. The attention distribution in Transformer partly reveals the correlation information of traffic flow across different traffic nodes in spatial and temporal dimensions, improving the model’s interpretability.
Table 1 lists the basic models, input information, datasets used and other key information of some methods. Based on Table 1, it can be seen that most of the early short-term traffic forecasting methods are based on a single detector to obtain time series data, such as traffic volume collected by sensors. However, the information contained in a single data source is usually difficult to meet the needs of accurate prediction. To this end, some studies have attempted to integrate multi-source information, give full play to the advantages of various network structures, and build large-scale complex network architectures to mine complex spatiotemporal correlation patterns in traffic flow data. These methods have indeed improved the prediction accuracy to a certain extent. However, the increase in model complexity will increase the training cost and computing resource requirements of the model, and ultimately affect the efficiency and scalability of practical applications (Lu and Osorio, 2018; Ji et al., 2022; Berghaus et al., 2024). Therefore, how to build an efficient and accurate traffic forecasting model is still one of the key issues that need to be overcome in the field of short-term traffic forecasting, and it is also the research goal of this paper.
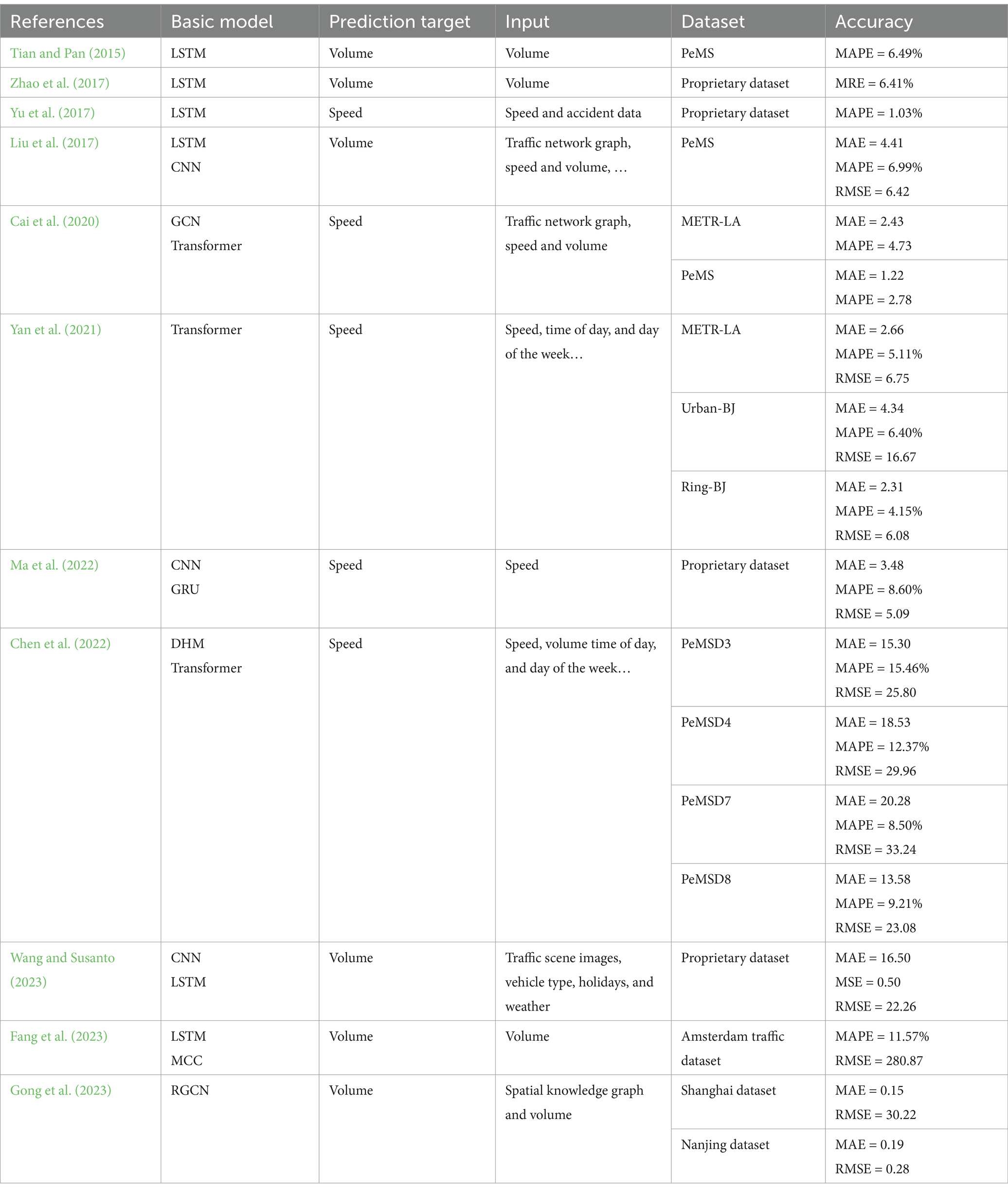
Table 1. Summary of research on short-term traffic forecasting.
3 Methodology 3.1 Structure of Trafficformer modelThe Trafficformer model introduced in this paper is designed for short-term traffic speed prediction at road network nodes, where traffic nodes represent the locations of traffic sensors on the road network. Figure 1 shows the structure of Trafficformer. As shown in Figure 1, the input of the model is the feature matrix St∈ℝI×N consisting of the traffic speeds of N consecutive steps of I nodes and the spatial mask MP∈ℝI×I calculated by the node distance and free flow speed. Among them, the feature matrix St is input into the traffic temporal feature extraction module, and the output is the matrix StC1∈ℝI×N containing the traffic flow time series features. As a priori knowledge, MP specifically guides the model to focus on those nodes that are more likely to affect each other in space, so that the model can focus on the key spatial relationship faster and improve the prediction performance. With StC1 and MP as input, the model realizes the extraction and embedding of spatial features based on the feature interaction module, and outputs the global feature matrix Zt∈ℝI×H containing the spatiotemporal correlation of traffic flow. Finally, with Zt as input, the predicted speed matrix of each node can be obtained through the speed prediction module. Below, the three modules in the model will be elaborated on in detail.
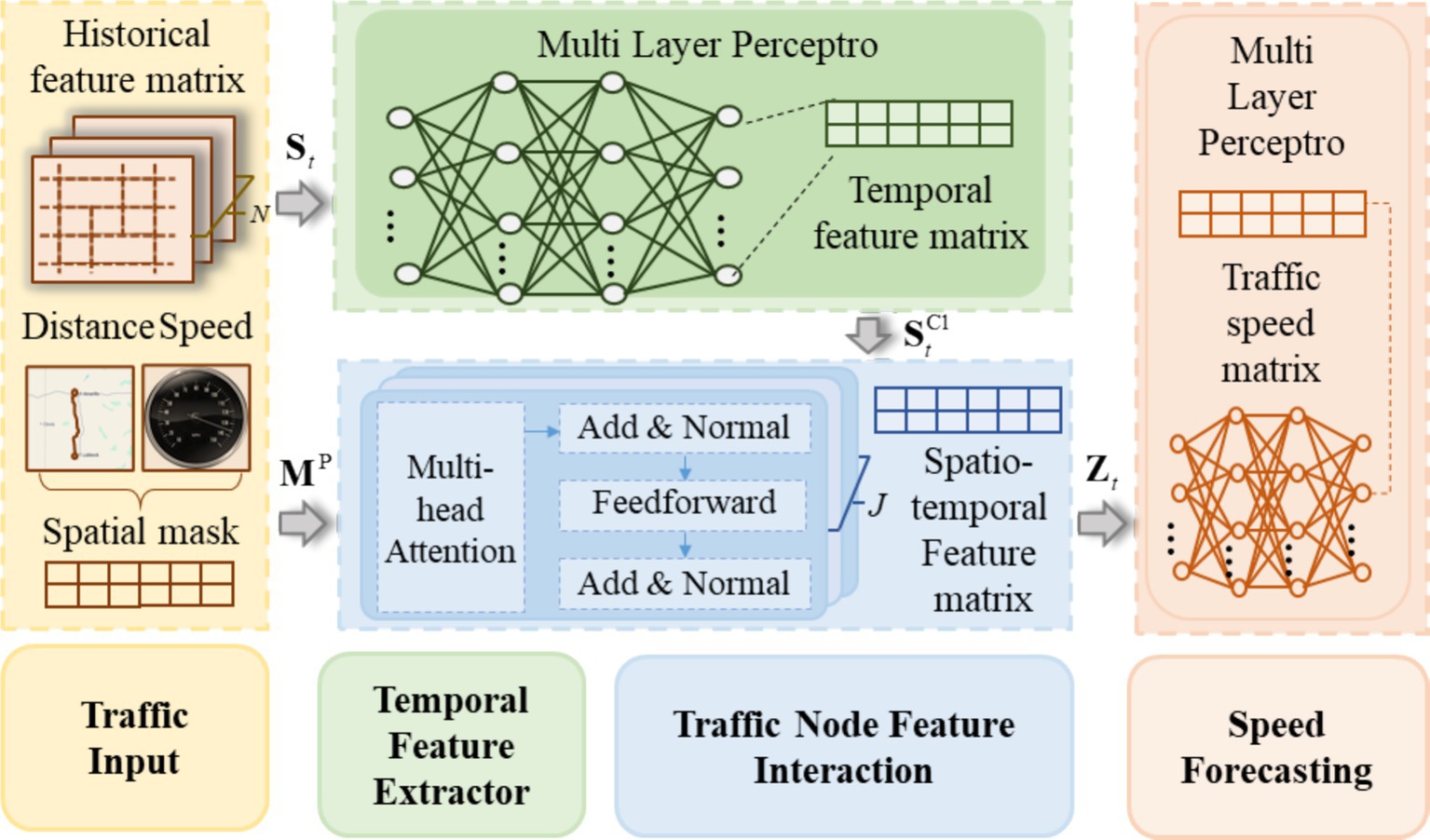
Figure 1. Structure of Trafficformer model.
3.2 Traffic node temporal feature extractorThe Temporal Feature Extractor for traffic nodes primarily consists of an MLP. MLP is a type of feedforward artificial neural network comprised of multiple layers of nodes. Each layer is fully connected to the next layer, and all nodes except the input nodes are neurons with non-linear activation functions. The use of activation functions introduces non-linearity to the output of the neurons, enabling MLP to handle non-linear separable problems effectively. Therefore, MLP is suitable for extracting temporal features with high uncertainty and non-linear characteristics. In this paper, the temporal feature extraction module for traffic nodes is a two-layer perceptron structure. It takes a feature matrix St as input composed of the historical speeds of traffic flow of I nodes over a continuous sequence of N statistical intervals starting from time t. The feature matrix undergoes two neural network linear layers, one normalization layer, and one non-linear layer successively, ending up with a temporal feature matrix StC1 that contains temporal information for each node, as shown in Equations 1–4.
StLin1=StWLin1+bLin1, (1)where StLin1∈ℝI×H is the output of the first neural network linear layer (H refers to the hidden layer dimensions of the temporal feature extractor of traffic nodes); WLin1∈ℝN×H and bLin1∈ℝI are learnable weight matrices, respectively.
To improve the accuracy of non-linear feature extraction and alleviate overfitting issues, a standardization layer and a non-linear layer have been introduced after the first linear layer. The standardization layer employed in this module is LayerNorm (Lei Ba et al., 2016). LayerNorm performs individual data sample training without relying on other data, which effectively avoids stability issues caused by the uneven distribution of mini-batch data in the batch normalization process during batch training. Furthermore, it eliminates the need to store mini-batch mean and variance and saves storage space. Considering the convergence speed of the model, the non-linear layer uses the ReLU activation function.
StLay=LayerNormStLin1, (2) StReLU=ReLUStrelu, (3) StC1=StReLUWLin2+bLin2, (4)where WLin2∈ℝH×H and bLin2∈ℝI are learnable weight matrices, respectively.
3.3 Traffic node feature interactionBased on the traffic node temporal feature extractor, the temporal feature of each node was obtained. However, the spatial features among the nodes remained unprocessed. Therefore, subsequent to the traffic node temporal feature extractor, the traffic node feature interaction module was constructed using the encoder in the Transformer. The input of this module is StC1 , which encompasses the temporal features of all nodes, and the output is the global feature matrix Zt that contains the spatiotemporal features of the nodes. The traffic node feature interaction module is constituted by L fundamental units. Each of these fundamental units mainly consists of a multi-head attention layer and a feedforward part. Among them, the multi-head attention layer is utilized to capture the complex spatial correlations and dependencies between different nodes by computing attention weights for each node’s features and generating new representations based on the weighted sum of other nodes’ features. And the feed-forward layer is employed to perform a non-linear transformation on the features obtained from the multi-head attention, mapping the input temporal feature matrix to the spatiotemporal feature output. It helps to further refine and enrich the feature representation, endowing the model with stronger discriminative ability. Next, a detailed introduction to the structures of the multi-head attention layer and the feedforward layer will be provided.
3.3.1 Multi-head attention layerThe multi-head attention mechanism, which is an evolved form of the self-attention mechanism, functions by concurrently executing multiple self-attention heads. This parallel operation empowers the mechanism to capture the intricate dependency relationships within traffic node feature sequences from various vantage points, thereby endowing the traffic flow prediction model with more elaborate and accurate feature representations. In the context of each individual self-attention head, the model first derives the query, key, and value feature matrices that correspond to the node’s feature vectors. Subsequently, the model computes the attention weights between nodes by leveraging the query matrix of a particular node and the key matrices of other nodes. Finally, through the utilization of the value matrices of other nodes and their respective attention weights, the model achieves the update of the node feature matrix. Equations 5–9, with the j-th ( j=1,2,…,J ) self-attention head serving as a representative example, illustrate the update process of the feature matrix Ztj∈ℝI×H at time t.
Ztj=softmaxAtjdkVtj, (9)where Qtj,Ktj,Vtj∈ℝI×H are the query, key, and value feature matrices in the j-th self-attention head respectively; Wj,Q,Wj,K,Wj,V∈ℝH×H are the weight matrices, which can be updated during the training process; Atj∈ℝI×I is the attention weight in the j-th self-attention head; softmax⋅ is a normalization function that scales the values of each element in the matrix between 0 and 1 by dividing the attention weights between nodes by the sum of the weights; dk is a scaling factor primarily used to mitigate the gradient disappearance issue introduced by the softmax function, which is numerically equal to the dimension H of the row vector kti,j of the node keys in the matrix Ktj .
Theoretically, the self-attention mechanism possesses the capacity to incorporate the information of all nodes for the generation of a comprehensive feature matrix. Nevertheless, in real-world applications, especially when confronted with complex traffic networks that encompass a large number of nodes, if the model were to compute the attention weights with respect to all nodes without discrimination, it would entail exorbitant computational overheads and might introduce a significant amount of superfluous noise and interference. In light of this, prior information has been elected to be employed to fabricate a spatial mask MP . This mask allows the model to ignore nodes that are less likely to be relevant spatially when calculating attention weights. This effectively narrows the computational scope, reduces the impact of noise, and ultimately enhances both training efficiency and model accuracy. To be more specific, initially, the travel time expended by a vehicle in traversing each node at the free flow speed VF is computed. Here, the free flow speed pertains to the velocity at which a vehicle travels under an ideal, unimpeded traffic flow scenario. Subsequently, by considering the connectivity traits among the nodes within the road network, those nodes whose travel time falls within the range of [0, TLimit ] are designated as strongly correlated nodes, while those with a travel time exceeding TLimit are classified as weakly correlated nodes. The mask elements corresponding to the strongly correlated nodes are assigned a value of 1, and those corresponding to the weakly correlated nodes are set to 0. This process culminates in the construction of the spatial mask. Equations 10, 11 takes node i and node i∗ ( i,i∗=1,2,…,I;i≠i∗ ) as examples to illustrate the calculation process of the spatial mask.
mi,i∗=0ifTi,i∗≤TLimit1elseTi,i∗>TLimit, (10) Ti,i∗=Li,i∗VF, (11)where Li,i∗ is the actual distance between nodes, mile.
At this stage, the calculation methodology for the attention weight Atj is revised as Equation 12:
Atj=QtjKtjT⊗MP, (12)where ⊗ denotes elementwise multiplication of matrices.
Once the feature matrix of each attention head have been computed, the global feature matrix Zt within the framework of the multi-head attention mechanism can be calculated in accordance with Equation 13. The multi-head attention mechanism’s network structure is presented in Figure 2.
Zt=ConcatZt1,Zt2,…,ZtJWtO, (13)
Figure 2. Structure of multi-head attention.
where Concat⋅ represents the concatenation operation, which specifically refers to horizontal concatenation of the feature matrices under different conditions in this paper; WtO∈ℝH×J×H is a learnable weight matrix that represents the importance of different attention angles based on a global perspective.
3.3.2 Feedforward networksThe feedforward network is a two-layer MLP structure. Unlike the normalization operation embedded within the traffic node’s temporal feature extraction component, the normalization operation in the feature interaction component is implemented separately by an external module. Therefore, the feedforward network consists only of fully connected layers and non-linear activation functions, as shown in Equation 14:
Ft=ReLUZtWF1+bF1WF2+bF2, (14)where WF1WF2∈ℝH×H , bF1,bF2∈ℝI are learnable weight matrices, respectively.
To build a deep model that effectively captures the complex spatiotemporal features in traffic flow data, Transformer employs residual connections around each module, followed by layer normalization, as shown in Equations 15, 16. In summary, the basic unit of the traffic node interaction module can be abstracted as the following equation, and the structure of the basic interaction module can be represented by Figure 3.
ZtC1=LayerNormZt+StC1, (15) ZtC2=LayerNormFt+ZtC1, (16)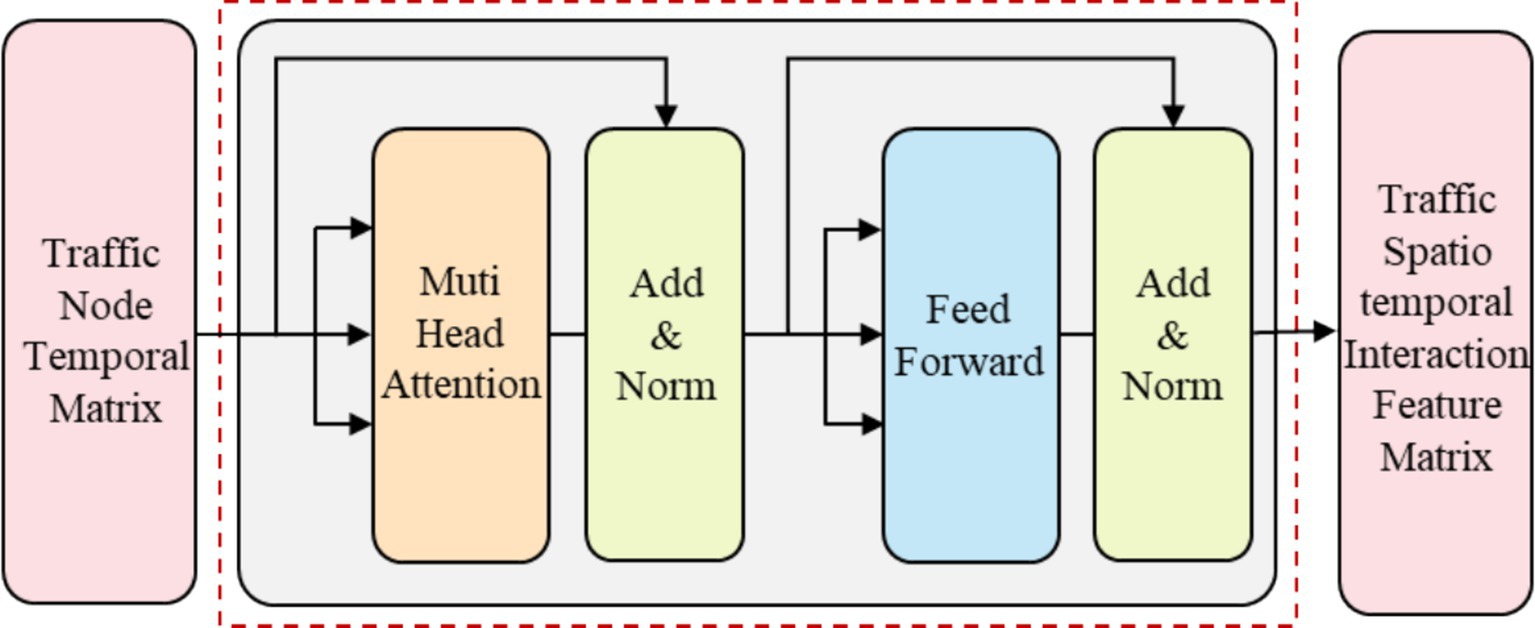
Figure 3. Feature interaction module structure of traffic nodes.
3.4 Traffic node speed forecastingThe traffic node speed forecasting module also follows the MLP structure, which is identical to the traffic node temporal feature extraction module. Both modules consist of two neural network linear layers, one normalization layer, and one non-linear layer. The difference lies in the input, output, and hidden layer dimensions of the network. The input of the traffic node speed forecasting module is the fused interaction feature matrix ZtC2 that captures the spatiotemporal correlations in the road network, while the output is the traffic speed matrix StC2∈ℝI for each node on road network at time step t+N+1 , as shown in Equations 17–20. MLP has various advantages of structure simplicity and highly parallel processing, which makes it computationally efficient for large-scale traffic forecasting tasks. This is why MLP has been chosen multiple times in this study for processing traffic node features.
StC2,Lin1=ZtC2WC2,Lin1+bC2,Lin1, (17) StC2,Lay=LayerNormStC2,Lin1, (18) StC2,ReLU=ReLUStC2,Lay, (19) StC2=StC2,ReLUWC2,Lin2+bC2,Lin2, (20)where WC2,Lin1∈ℝH×H∗ , bC2,Lin1∈ℝI , WC2,Lin2∈ℝH∗×1 and bC2,Lin2∈ℝ1 are all learnable weight matrices; H∗ denotes the dimensions of hidden layers in the traffic node speed forecasting module.
4 Experiments 4.1 Dataset descriptionIn this study, the efficacy of the method was evaluated by leveraging the publicly available Seattle Inductive Loop Detector Dataset V1 (referred to as the Loop dataset hereafter). This dataset consists of speed information collected from loop detectors deployed on four highways in the Seattle area: I-5, I-405, I-90, and SR-520. Each blue icon in Figure 4 represents a milepost on the road network, with a total of 323 mileposts along the entire route. For any given milepost, the speed information is obtained by averaging the data from multiple detectors on the corresponding main road direction. The dataset used in this study is available at the following link: https://github.com/zhiyongc/Seattle-Loop-Data.
The dataset contains the complete spatiotemporal speed information for the highway system in 2015, with a time interval of 5 min for each detector. The dataset comprises over 3.83 million records. In terms of the principle of algorithmic consistency, the model program was implemented based on the opensource code from a previous study (Cui et al., 2019). Several comparative experiments were performed using the identical dataset. The dataset was partitioned into three parts: training set, validation set, and test set, maintaining a 7:2:1 proportion. The training set served the purpose of model training, the validation set was reserved for finetuning and optimizing the parameters, and the test set was designated for evaluating the generalization performance of the model. Additionally, the road speed limit was set to 60 miles per hour, so VF=60 mph is obtained. In the preprocessing stage, each speed value in the speed matrix is divided by the maximum speed value in the data set to normalize the speed data to the [0, 1] interval. This normalization operation is of great significance. It unifies the data scale, effectively improves the efficiency and stability of model training, and avoids the model’s excessive attention to certain features due to differences in data scale.
4.2 Experimental settings 4.2.1 BaselinesIn this paper, the Trafficformer model is compared with several established baseline models. These baseline models are carefully selected to represent a diverse range of techniques in the traffic flow prediction field, including both classic linear methods such as ARIMA and SVR, which possess well-established theoretical foundations but also come with certain limitations, and various nonlinear models like DiffGRU, LSTM, DMLP, LSTM+MLP, and TGG-LSTM. By comparing with these models, a thorough analysis of their performance is provided, and the distinct advantages of Trafficformer in different traffic forecasting scenarios are highlighted.
1. SVR: Support Vector Regression model (Hamed et al., 1995).
2. LSTM: Long Short-Term Memory network (Schmidhuber and Hochreiter, 1997).
3. ARIMA: Autoregressive Integrated Moving Average model (Smola and Schölkopf, 2004).
4. DiffGRU: An improved model based on Convolutional RNN. The spatial dependencies between traffic nodes are captured using Spectrogram Convolution, and the temporal dependencies are captured using enc-decoding components with scheduled sampling (Li et al., 2017).
5. TGG-LSTM: A DL model based on LSTM, which modeled the spatial correlations between different traffic nodes using graph convolution and utilized LSTM for vertical mining of the historical information of traffic flow (Cui et al., 2019).
6. DMLP: A network model consisting of two double-layered perceptions, where each MLP is responsible for traffic feature extraction and prediction, respectively (Wang Z. et al., 2024).
7. LSTM + MLP: A comparative algorithm proposed in relation to LSTM, aiming to highlight the unique significance of designing traffic flow feature extraction and prediction as separate modules. It consists of a single layer of LSTM for extracting traffic feature states and a two-layer perceptron for predicting traffic speed, which effectively improves the analysis of traffic flow data.
4.2.2 Training parametersAll LSTM and MLP layers have the same weight dimensions, with a hidden layer size of 128. The input traffic flow data was composed of the historical speeds of traffic flow of 323 nodes over a continuous sequence of 10 artistical intervals starting from time t, denoted as N=10 . The predicted time step is 1. The size of the node connectivity constraint indicator TLimit can be adjusted to observe the effects of feature extraction and interaction within different spatial ranges. Through multiple experiments, the value of TLimit was set to 5. This means that each traffic node interacts with other traffic nodes that can be reached within 5 min of free flow speed from that node. Each model is trained with the goal of minimizing the MSE, which serves as a reliable and commonly used metric to quantify the disparity between the predicted and actual values. The optimization process is carried out using the AdamW optimizer, a sophisticated variant proposed by Loshchilov (2017). This optimizer ingeniously applies weight decay, a technique that effectively curtails the gradient of model parameters. By doing so, it not only mitigates the risk of overfitting but also substantially lowers the computational complexity associated with training. In terms of the learning rate strategy, the ReduceLROnPlateau approach (Ruder, 2016) has been adopted. This strategy is designed to dynamically adjust the learning rate based on the evaluation metrics. The initial learning rate is meticulously configured at 1E-3, a value determined through an extensive series of preliminary experiments. A decay factor of 0.2 is employed, which means that whenever the performance metric plateaus, the learning rate is reduced by this factor. The minimum learning rate is set at 1E-6 to ensure that the learning process does not stagnate completely. The total number of iterations is capped at a maximum of 150 to prevent excessive training and potential overfitting.
To further safeguard the convergence and generalization ability of the model, a mechanism to adaptively reduce the learning rate has been implemented. Specifically, if there is no observable improvement in performance for 10 consecutive epochs, the model will automatically reduce the learning rate. This adaptive learning rate adjustment strategy allows the model to finetune its learning pace and explore the parameter space more effectively, ultimately leading to better convergence and performance. In addition to the aforementioned strategies, a crucial regularization technique known as Early Stopping has been incorporated. The Early Stopping strategy acts as a safeguard against overfitting by closely monitoring the performance of the model on the validation set. Once the performance on the validation set ceases to improve, the training process is promptly halted. This ensures that the model is trained sufficiently to capture the underlying patterns in the data while preventing it from overfitting to the training data and losing its generalization capabilities. Overall, these meticulously designed optimization and regularization strategies work in tandem to enhance the performance, stability, and generalization ability of the model, enabling it to effectively handle the complex and dynamic nature of the t
Comments (0)