
Remember me
Accurate yield estimation is paramount for effective crop management, allowing growers to optimize fertilization, optimize resource utilization, and maximize yield per unit area and time. However, conventional yield estimation methods, predominantly reliant on sampling and visual inspection, are labor-intensive, time-consuming, costly, and often fall short of precision. Advancements in artificial intelligence and computer vision have presented promising solutions for automating fruit yield estimation. Object recognition models based on convolutional neural networks (CNNs) offer high-precision litchi fruit recognition, particularly under natural conditions. This technology is crucial for achieving automated yield assessment and supporting the development of agricultural automation (Sultana et al., 2020; Kheradpisheh et al., 2018; Liang and Hu, 2015).
Traditional machine vision techniques typically involve manual feature extraction for parameters such as grayscale, color, texture, and shape. In contrast, deep learning approaches leverage convolutional neural networks to automatically extract high-dimensional features, which is advantageous for complex tasks such as object detection. In the context of fruit target detection, significant progress has been made through various CNN-based methods. For instance, Sun et al. (2018) introduced a tomato detection approach using an improved Faster R-CNN with ResNet-50 as the feature extractor, demonstrating improved accuracy under occlusion but limited real-time performance. Similarly, Tian et al. (2019) developed an enhanced YOLO-V3 model using DenseNet to detect apples at different growth stages, achieving effective detection under occlusion and overlapping but with computational challenges. Other works have targeted grapes, strawberries, and litchi, using various improvements to YOLO architectures to address specific detection requirements (Fang et al., 2021; Yijing et al., 2021; Latha et al., 2022; Wang Z. et al., 2022).
Despite these advancements, litchi fruit detection faces unique challenges, particularly due to the lack of a public dataset and the complexities of natural agricultural environments. Existing studies in litchi detection, including those by Peng et al. (2022) and Wang L. et al. (2022), primarily focus on enhancing detection speed and accuracy through innovations such as dense connections, residual networks, and attention mechanisms. However, detection under natural scenes remains challenging due to the small size of litchi fruits and their high degree of occlusion with leaves and other fruits. These conditions often lead to misdetections, especially in cases where inter-class occlusion results in highly similar visual features between overlapping objects.
Multimodal learning presents a promising avenue for enhancing litchi detection by integrating information from multiple sensory and data modalities. This approach addresses the limitations of vision-only methods (Rana and Jha, 2022; Hu et al., 2021; Cheng et al., 2017). By combining visual data with additional inputs, such as spectral, thermal, or spatial data from high-resolution sensors, more robust feature extraction can be achieved, leading to improved detection accuracy and resilience to occlusion. For instance, spectral data can distinguish between litchi fruits and leaves based on subtle variations in light reflectance, while spatial data from LiDAR or depth sensors can aid in resolving overlapping objects by capturing distance and shape information. These multimodal approaches provide complementary perspectives that enhance feature representations, enabling CNN-based models to attain higher precision in intricate agricultural scenarios (Guo et al., 2019; Suk et al., 2014; Ngiam et al., 2011).
To address the aforementioned challenges, this paper proposes a novel multimodal target detection method, denoted as YOLOv5-Litchi. This method is based on an enhanced YOLOv5s architecture, with improvements made to the neck and head layers, modifications to positioning and confidence losses, and the incorporation of multimodal data with sliding-slice prediction. These enhancements enable improved litchi detection under challenging natural conditions. Notably, this method not only advances the technical capability for litchi yield estimation but also underscores the potential of multimodal learning in agricultural automation. It offers a scalable solution for yield estimation and resource management in diverse farming environments.
In this study, we hypothesize that the proposed modifications to the YOLOv5 architecture will significantly enhance the detection accuracy of litchi fruits, particularly under challenging conditions commonly found in natural agricultural environments. These enhancements, including the incorporation of TSCD detection heads, simplification of the Neck structure to FPN, and optimization of loss functions, are expected to improve precision, recall, and mean Average Precision by effectively addressing issues such as small target sizes, dense occlusions, and complex backgrounds. Specifically, we anticipate an increase in detection accuracy of up to X% compared to the baseline YOLOv5 model, highlighting the effectiveness of these modifications for automated yield estimation tasks.
2 Related workIn recent years, deep learning has significantly advanced agricultural automation, especially in detecting and classifying fruits under natural conditions. Traditional methods for fruit detection relied on manual feature extraction, such as analyzing grayscale, color, and texture, but these have largely been replaced by deep learning models that automatically extract high-dimensional features. This shift has made deep learning models particularly suitable for complex detection tasks (Saleem et al., 2021; Tian et al., 2020; Attri et al., 2023).
Research on fruit detection has evolved significantly with advancements in deep learning, especially through improvements in convolutional neural networks tailored for high-precision object detection. Object detection models such as Faster R-CNN, YOLOv3, YOLOv4, and YOLOv5 have demonstrated considerable success in detecting various fruits under challenging conditions (Koirala et al., 2019; Ukwuoma et al., 2022). Early fruit detection models, for example, have often relied on feature extraction methods that utilize grayscale, color, and texture for image analysis, proving limited under complex environmental factors. However, CNN-based models now provide enhanced robustness by learning high-dimensional, multiscale features that improve precision in occlusion-rich scenes (Sa et al., 2016; Koirala et al., 2019).
Several state-of-the-art approaches have emerged, particularly with improvements to YOLO architectures that address specific detection needs. For instance, Sun et al. (2018) applied Faster R-CNN with ResNet-50 to improve detection accuracy under occlusion, while Tian et al. (2019) employed YOLOv3 with DenseNet for apple detection across growth stages, achieving high precision even under overlapping conditions. Similarly, studies on grapes and strawberries using enhanced versions of YOLO models have shown that incorporating mechanisms like attention modules and depth-separable convolution layers can improve mean Average Precision (mAP) scores and detection speeds, making these approaches suitable for real-time agricultural applications (Latha et al., 2022; Cuong et al., 2022).
For litchi detection specifically, research remains limited. The absence of a large, standardized dataset and the small size and dense clustering of litchis pose unique challenges. Peng et al. (2022) addressed some of these challenges by enhancing YOLOv3 with dense connection and residual modules, yielding improved detection precision and speed for litchi fruits in natural scenes. Some recent studies also further extended this work by modifying YOLOv5 with ShuffleNet v2 and CABM attention mechanisms, enabling faster detection and more accurate yield estimates. Another approaches, for example, incorporate additional attention mechanisms into YOLOv5 with CIoU loss functions, achieving a balance between model size, accuracy, and speed (Zhang et al., 2018; Fang et al., 2022).
Multimodal learning has recently emerged as a solution to limitations in single-modality detection systems, particularly for small and densely packed objects like litchis. Studies combining visual data with spectral, thermal, or spatial inputs have shown that multimodal networks can better distinguish objects from background features, reduce occlusion issues, and improve overall detection accuracy (Zhao et al., 2024; Zhang et al., 2020; Kandylakis et al., 2019). Spectral data, for example, can aid in differentiating litchi fruits from leaves based on reflectance properties, while spatial information from LiDAR or depth sensors enhances 3D feature representation, which is valuable in resolving object overlap (Rahate et al., 2022; Barua et al., 2023).
Given these advancements, the current study proposes a YOLOv5-based model that leverages multimodal learning techniques and an optimized architecture to address the complexities of litchi detection in natural scenes (Zohaib et al., 2024; Kolluri and Das, 2023; Li et al., 2019). By incorporating modified neck and head layers, sliding-slice predictions, and enhanced loss functions, YOLOv5-Litchi aims to improve detection accuracy, making it a robust tool for automated yield estimation and resource management in agricultural systems (Xu et al., 2024; Aledhari et al., 2021; Sharma et al., 2020).
In general, existing methods for fruit detection have achieved varying levels of success by leveraging different enhancements to YOLO architectures and other convolutional neural network-based models (Wang et al., 2019; Liu et al., 2019). For instance, some works utilized an improved Faster R-CNN with ResNet-50, achieving higher precision in occluded environments but with limited real-time performance due to computational complexity. Similarly, Tian et al. (2019) employed YOLOv3 with DenseNet to detect apples at various growth stages, demonstrating effective detection under occlusion but facing challenges in scalability and processing speed. Specific to litchi detection, Peng et al. (2022) enhanced YOLOv3 with dense connections and residual modules, achieving notable improvements in precision but with limited capability in densely clustered scenes. Comparatively, studies employing multimodal approaches, such as combining visual and spectral data, have shown improvements in detection accuracy but often require specialized hardware and increased computational resources. These methods highlight the trade-offs between accuracy, speed, and hardware requirements. In contrast, our approach integrates TSCD detection heads, simplified Neck structures, and optimized loss functions to address these limitations, achieving significant improvements in precision, recall, and mAP without excessive computational overhead, thereby providing a balanced and scalable solution for litchi detection.
3 MethodologyThis study focuses on improving the detection of small and occluded litchi fruits in natural agricultural environments, addressing specific challenges such as dense clustering and complex backgrounds. The proposed modifications to YOLOv5, including TSCD detection heads and optimized loss functions, contribute to enhancing detection accuracy and reliability, advancing automated yield estimation in agriculture.
3.1 Image acquisition and dataset constructionThe main research object of this paper is mature litchi fruit. The collected litchi images are from the National Litchi Longan Industrial Technology System Demonstration Base in the North Campus of Shenzhen Vocational and Technical College, and the shooting equipment is a smart phone. A total of 103 images are collected. Figures 1A, B is to adjust the brightness of the picture; Figure 1C the picture is randomly cropped to 960 × 960 size; Figures 1D–F is rotated counterclockwise by 90°, 180°, and 270°; Figures 1G, H is horizontal flip and vertical flip; Figure 1I The picture shows the increase of salt and pepper noise.

Figure 1. Effects of data enhancement.
After the above image enhancement method, 611 images with a total of 86,169 labels are obtained. According to the divided training set and verification set, the above five methods of data expansion are carried out. Then half of the images of each type are randomly selected to obtain 482 training sets with a total of 66,120 labels, and 129 verification sets with 15,371 labels. The specific division of data sets is shown in Table 1, and the process of data expansion is shown in Figure 2.
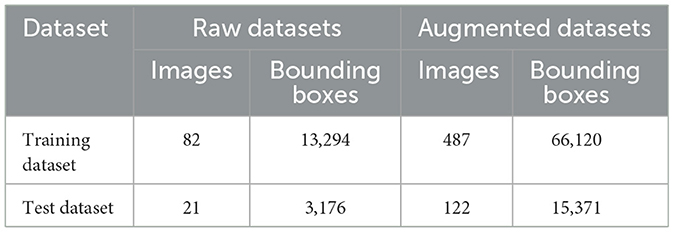
Table 1. Image composition of dataset.
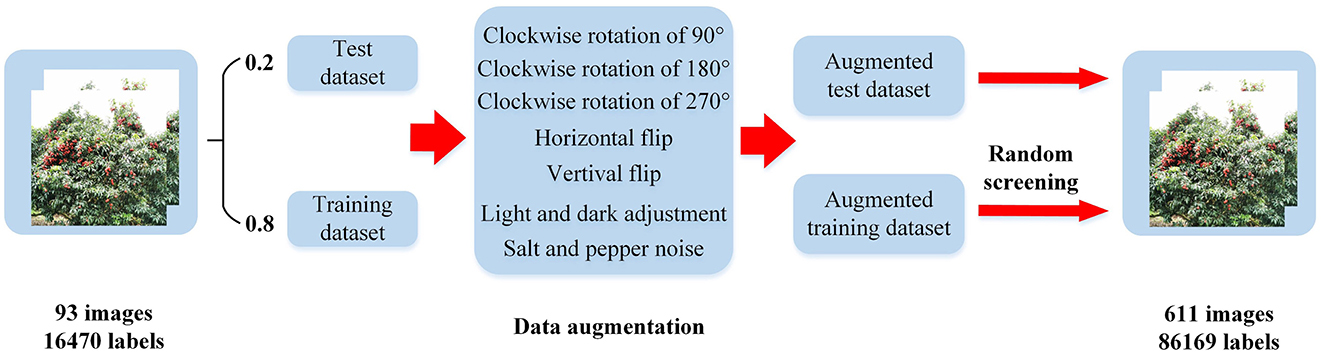
Figure 2. Flowchart of dataset construction.
Figures 3A, C shows that due to random clipping, the size of the expanded label increases somewhat. The normalized width increases from 0.05 to about 0.12, and the normalized height increases from 0.06 to about 0.14, thus enriching the size of the label. Figures 3B, D shows that the label distribution after data expansion is more uniform than before, and litchi labels are basically found in every position of the whole figure, thus enriching the position of labels.
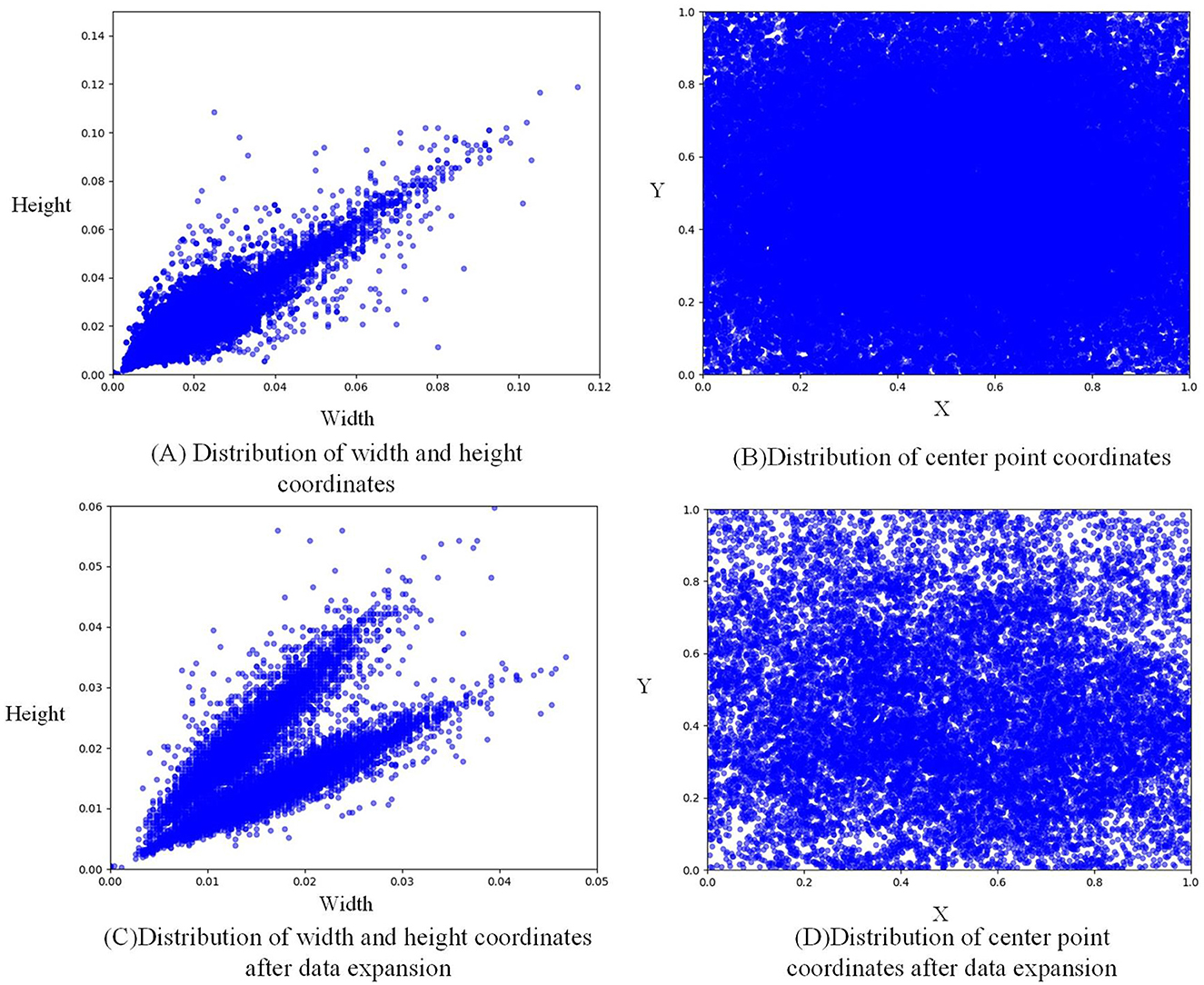
Figure 3. Label distribution visualization.
3.2 Annotation of imagesLabelImg annotation tool was used to label litchi fruit with the collected images. The marking rules are as follows: (1) mark according to the smallest rectangle of the visible outline of litchi; (2) For litchi with occlusion, the litchi in the occluded part should be marked as its actual shape, and if the occluded area exceeds 80%, it will not be marked; (3) Litchi with fuzzy distortion in the distance will not be marked. For each hand-marked litchi image, the LabelImg tool will automatically generate the corresponding.txt file, which contains five types of information: each annotated category, the normalized center point coordinates of the annotated rectangle box and the normalized width and height information of the annotated rectangle box respectively. According to the above annotation methods, the litchi image annotation example is shown in Figure 4. Figure 4A is the operation interface of the LabelImg annotation tool, and Figure 4B is the label file generated after annotation.

Figure 4. Litchi image annotation (A) LabelImg annotation software, (B) TXT format file.
In Figure 4B, the first column of the label file represents the category; the second and third columns represent the normalized center coordinates x̄ and ȳ of the label frame; the fourth and fifth columns represent the normalized width and height of the label frame w̄ and h̄; x, y, w, and h respectively represent the center point coordinates and width and height of the label frame before normalization; H and W represent the width and height of the image. The normalization formula is as follows:
Noteably, while the dataset is relatively small, it was carefully curated to ensure representativeness by including images with diverse lighting conditions, occlusion levels, and growth stages of litchi fruits. This rigorous selection process enhances the dataset's robustness, enabling the model to generalize effectively to the complexities of natural agricultural environments.
3.3 YOLOv5 architectureYOLOv5s target detection model mainly consists of Backbone network, Neck network and prediction layer. The function of the backbone network is to extract image features. The backbone network of YOLOv5s model adopts CSPDarkNet53 structure. The function of the Neck layer is to perform feature fusion on the features extracted from the backbone network. FPN (Lin et al., 2017) + PAN (Liu et al., 2018) is used to enhance the degree of feature fusion. FPN is used to transmit strong semantic features from deep to shallow, while PAN is used to transmit strong positioning features from shallow to deep, which improves the network's ability to recognize features of different feature layers. The role of the Head layer is to predict the features of three different dimensions to obtain the category and location information of the network prediction. In this paper, multi-scale features are extracted based on YOLOv5s network. Firstly, the FPN+PAN structure of Neck layer is simplified to FPN, the number of detection heads is increased from 3 to 5, and two scale TSCD detection heads of 80 × 80 (p2) and 160 × 160 (p3) are set, in order to improve the detection capability of small targets. Then, the positioning Loss and confidence Loss are optimized, and the positioning loss is replaced with EIoU Loss, and the confidence loss is replaced with Varifocal Loss (VFLoss for short), so as to improve the positioning accuracy of the detection box and further improve the ability of the network to detect dense targets. The network structure of the improved YOLOv5s network model, renamed YOLOv5-Litchi, is shown in Figure 5.

Figure 5. The network structure of YOLOv5-Litchi.
The TSCD (Two-Scale Contextual Detection) heads enhance YOLOv5-Litchi by improving small object detection and addressing dense occlusions. The TSCD structure utilizes multi-resolution feature maps generated through up-sampling and channel splicing. Specifically, the feature map of 80 × 80 resolution is combined with an up-sampled 160 × 160 map and fused with additional low-resolution data to form a rich contextual feature representation. This integration allows the TSCD heads to detect small targets more effectively by preserving spatial details and integrating multi-scale context, leading to notable improvements in precision, recall, and AP metrics. Experimental results confirm the structure's contribution to detecting challenging litchi fruit instances in natural environments.
Firstly, the specific structure of TSCD Head is understood. As shown in Figure 6A, the resolution of feature figure output from the neck layer is 80 × 80. First, after up-sampling, the feature figure with a resolution of 160 × 160 is splicing in channel dimension. Then the convolution operation is used to down-sample the spliced feature map to get 256 × 80 × 80. Secondly, in order to fuse low-resolution features, feature figure with a resolution of 40 × 40 is up-sampled to get 256 × 80 × 80. Finally, the two obtained feature maps are combined with to get a 768 × 80 × 80 feature map, which is input into the Head as a new P2 feature map. The same is true for Figure 6B.
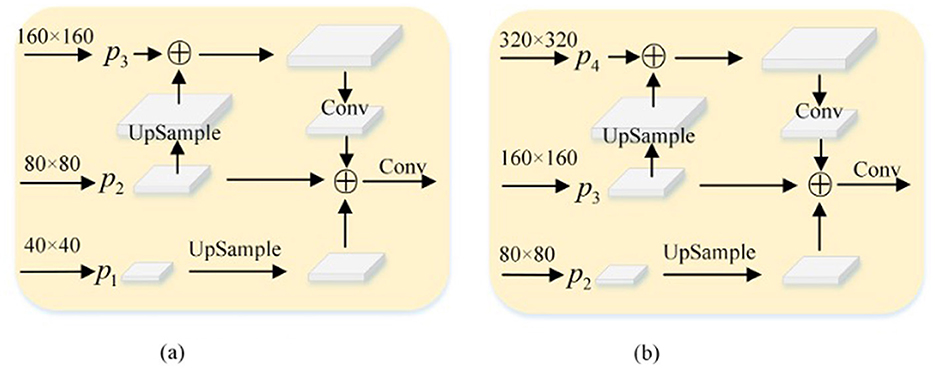
Figure 6. TSCD structure. (A) TSCD Head1 (768 × 80 × 80). (B) TSCD Head2 (512 × 160 × 160).
Table 2 shows the experimental comparison results of whether the Head layer uses TSCD structure. It can be seen from the table that when this structure is used in the network, AP increases by 2.4%, while the accuracy rate and recall rate increase by 1.7 and 2.1%, respectively. However, due to the addition of many up-sampling and convolution operations, the number of parameters in the model also increases accordingly.
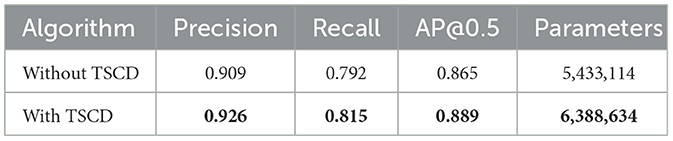
Table 2. Experiments on whether to include TSCD.
Subsequently, examine the four enhanced structures of the Neck and Head layer in YOLOv5, as depicted in Figure 7. It becomes evident that each of the four structures sets two TSCD heads as detection heads within the Head layer. Figures 7A, B illustrates that the Neck layer is the network structure of FPN+PAN, while Figures 7C, D demonstrates that the Neck layer is the network structure of FPN. Although FPN+PAN effectively integrates the features of each layer, it also introduces a substantial number of parameters. Consequently, when redesigning the Neck layer network, the approach adopted by YOLOv6 serves as a reference. YOLOv6 introduces a reduction in the three decoupling heads of classification Head(cls), regression Head(Reg), and confidence Head(obj) to two decoupling heads of classification Head(cls) and regression Head(Reg), which is equivalent to a subtraction of the network but yields superior results. In this paper, after simplifying FPN+PAN to FPN, the experiment on the litchi dataset also achieved improved results. The experimental results are presented in Table 3.
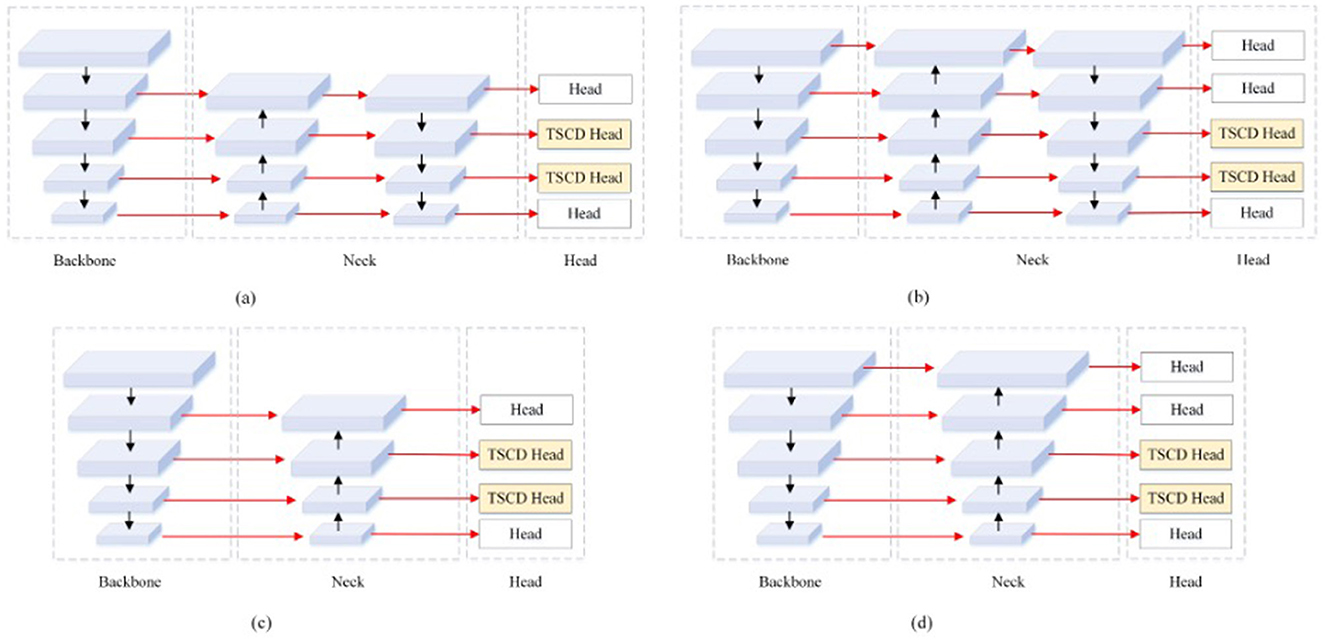
Figure 7. Four TSCD Head structures. (A) yolov5s_TSCD_V1. (B) yolov5s_TSCD_V2. (C) yolov5s_FPN_TSCD_V1. (D) yolov5s_FPN_TSCD_V2.
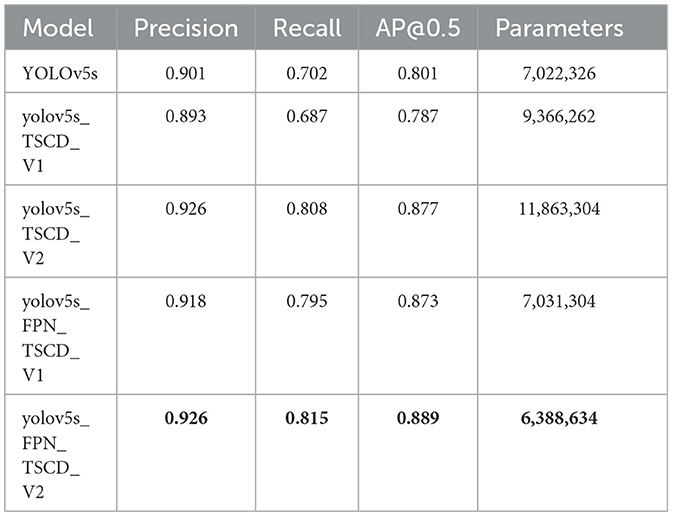
Table 3. TSCD head experiments.
According to the experimental results, after adding one detection head and replacing two of the detection heads with TSCD detection heads, as depicted in Figure 7A, the model's performance deteriorated compared to the original YOLOv5s. However, when the FPN+PAN structure was simplified into the FPN structure, the AP, accuracy, and recall rates, respectively, increased by 7.2% in comparison to YOLOv5s. The AP value increased by 1.6%, and the accuracy and recall rates increased by 9.3%. When the number of detection heads was increased to five, the FPN structure attained optimal performance, and the AP value reached 88.9%, which was 8.8% higher than YOLOv5s.
3.4 Improvement of loss functionYOLOv5s will respectively classify, locate and predict the confidence of the feature map output of the Head layer, so it also corresponds to the calculation of the three losses to gradually optimize the network. However, since this paper studies single-category target detection, the loss function only includes two categories, Losseiou represents the positioning loss. Lossconf is used to calculate the degree of overlap between the prediction box and the real box. Lossconf is the confidence loss, and the confidence is used to represent the reliability of the prediction box, and the prediction box with possible targets is screened. The total loss formula of YOLOv5-Litchi is as follows:
Loss=Losseiou+Lossconf (5)Binary cross entropy loss is used for classification and confidence loss in the original YOLOv5s, and its formula is as follows:
BCE={-log(ŷ)if y=1-log(1-ŷ)if y=0 (6)where y represents the label of the sample, 1 represents the litchi, 0 represents the background, and ŷ represents the predicted value of the network. In order to make the network adapt to the detection of dense targets, the BCE loss is replaced by the VFLoss function, the formula is as follows:
VFL={-q(qlog(ŷ)+(1-q)log(1-ŷ))if q>0-αŷγlog(1-ŷ)if q=0 (7)where ŷ is the predicted value of the network, q represents the label of the sample, where the γ is set to 1.5, which can be scaled by the γ factor. When YOLOv5 calculates the confidence loss, q is designed as the IoU between the predicted BBox and GT Box for positive samples, and q is designed as 0 for negative samples. It can be seen from Equation 7 that VFLoss only reduces the weight of negative samples in loss, but does not change the weight of positive samples. It makes the training pay more attention to high-quality positive samples, thus improving the detection performance.
The original YOLOv5's positioning loss adopts CIoU loss, which also takes into account the overlap area, center distance, and aspect ratio of bounding box regression. The formula is as follows:
LCIoU=1-IoU+ρ2(b,bgt)c2+βν (8) ν=4π2(arctanwgthgt-arctanwh)2 (10)where ρ2(b, bgt) represents the Euclidean-style distance between the center point of the prediction box and the center box, c represents the diagonal length containing the minimum outer box of the prediction box and the real box, β is the weight function, and ν is the aspect ratio measurement function.
The aspect ratio in CIoU uses relative values, which cannot guarantee its accuracy and does not consider the balance problem of difficult and easy samples. In order to better deal with litchi fruit detection in dense scenes, the boundary frame loss function EIoU is introduced to solve this problem. On the basis of CIoU, EIoU converts the aspect ratio into the difference between the width and height of the predicted frame and the minimum external frame. EIoU's loss function formula is as follows:
LEIoU=LIoU+Lloc+Lasp =1-IoU+ρ2(b,bgt)c2+ρ2(w,wgt)cw2+ρ2(h,hgt)ch2 (11)Among them, ρ2(b,bgt)c2, ρ2(w,wgt)cw2, and ρ2(h,hgt)ch2 represent center point loss, width loss, and length loss, respectively. Specific parameters are shown in the Figure 8.

Figure 8. EIOU loss for bounding box regression.
Generally, the process of target detection network prediction will scale the input picture to a specific size in equal proportion, for example, it can be set to the same size as the training size (640 × 640). For large-resolution pictures, if the picture is compressed in equal proportion, information will be lost, which will easily lead to the loss of small-target prediction, and the final network prediction result will be poor. And if the size of the input image is set larger, the network prediction time will also be longer.
Therefore, this paper draws on YOLT's processing method for high-resolution image prediction, and improves the model prediction. The improved prediction process is as follows: First, the input image is clipped by sliding slice, and the image is clipped into several copies in the direction of X and Y axes, each image has a certain overlap area; Then the clipped pictures are predicted separately, and each predicted result is spliced. Finally, the NMS method is used to filter out the redundant prediction boxes and get the final prediction result. This makes it possible to predict high-resolution images without loss of information by maintaining the original size and making good predictions for small targets.
The sliding slice method mainly consists of the following four steps:
Step 1: Define the slice size and Overlap Rate (Overlap Rate before and after the overlap rate between the two slices in proportion to the slider area);
Step 2: Horizontally, slices slide to the right at a certain step (Stride = 1 - Overlap Rate) (as shown in Figures 9A, B). When slices slide to the rightmost position, if the image boundary is exceeded, the Overlap Rate of slices needs to be adjusted, as shown in Figures 9A–C.
Step 3: In the vertical direction, similarly, slices slide vertically downward at a certain Stride = 1 - Overlap Rate. When slices exceed the image boundary, the Overlap Rate of slices is adjusted.
Step 4: Repeat steps 2–3 until the slice covers the entire picture.
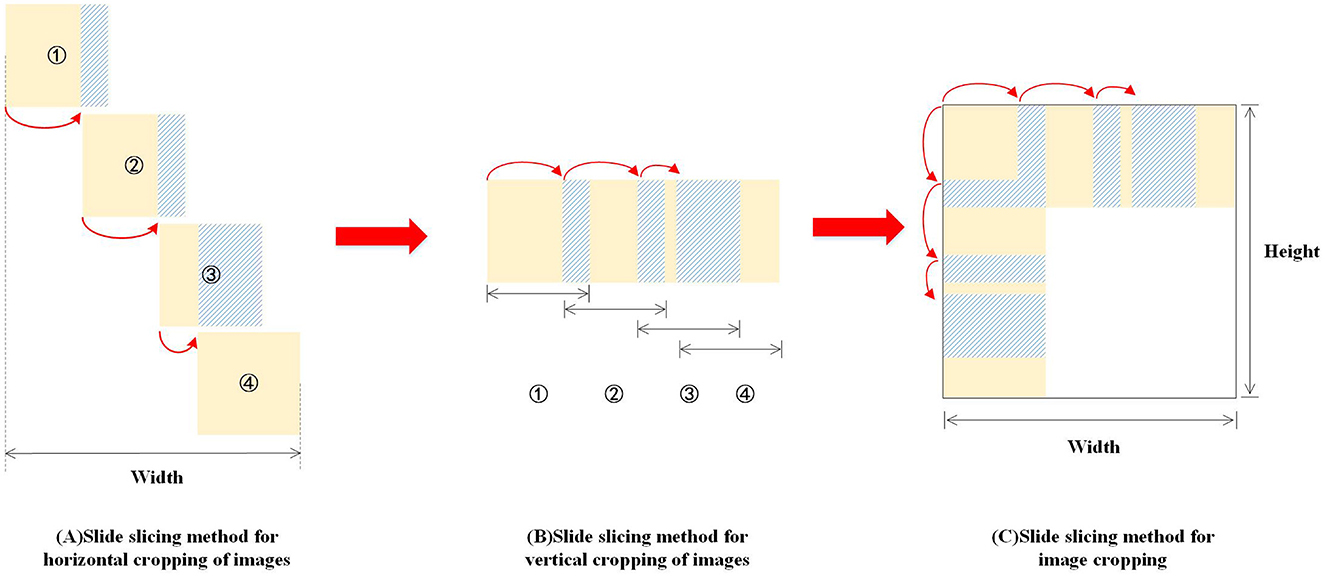
Figure 9. Sliding slice illustration.
All the images obtained by sliding slice are input into the network for prediction, and the prediction results of each image are obtained. Since each image has overlapping areas, it is necessary to use the non-maximum suppression method to screen the prediction boxes obtained, and the non-maximum suppression also has four steps:
Step 1: Set the threshold of the IoU.
Step 2: Sort all prediction boxes in the same category according to classification confidence, and select the detection box with the highest confidence at present;
Step 3: Traverse all other detection boxes and delete the prediction box whose IoU of the highest confidence box is higher than the threshold.
Step 4: Repeat steps 2–3 until all boxes are processed. As shown in Figure 10, a total of 642 litchi targets were counted after block prediction and splicing, and 328 litchi targets could be screened after NMS, among which most of the filtered prediction boxes were targets that were repeatedly predicted.
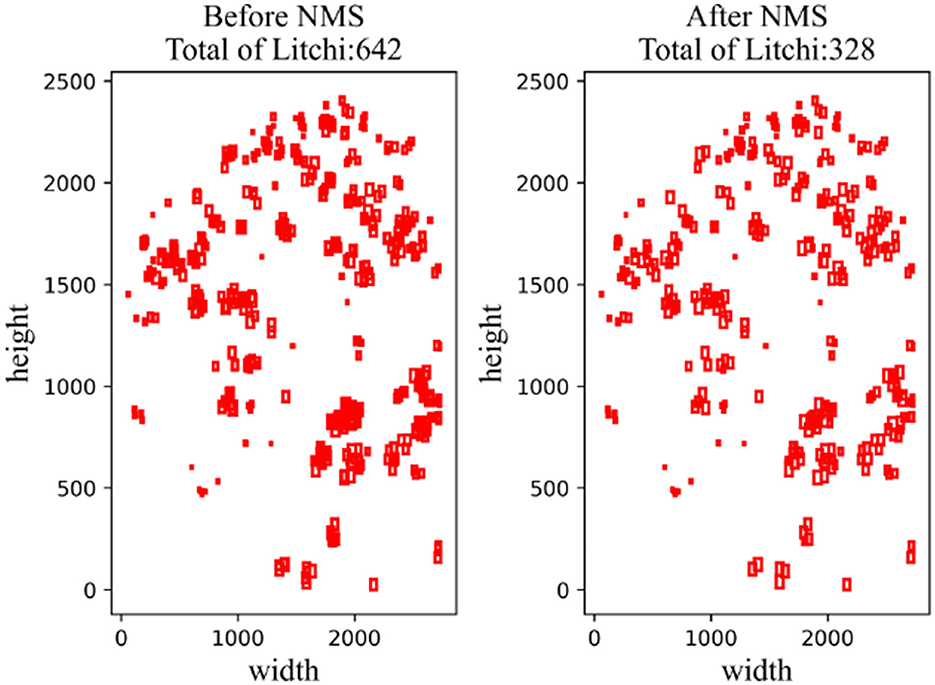
Figure 10. Comparison images before and after NMS.
4 Experiments 4.1 SettingsIn this paper, VsCode is used to build and improve the YOLOv5s network model. The processor model of the test platform is Intel Core i5-12400F, and the graphics card model is NVIDIA GTX4060. Deep learning environments such as python3.8.0, cuda11.6, and cudnn8302 have been deployed on Windows 10. Detailed device and environment parameters are shown in Table 4. All benchmarked models, including YOLOx, YOLOv6, and YOLOv8, were re-trained on the same litchi dataset to ensure a fair comparison of performance. This approach eliminates potential biases introduced by pretrained weights and ensur
Comments (0)